
In the dynamic realm of artificial intelligence, Data-Centric AI stands out as a transformative paradigm that places data at its core. Unlike traditional approaches, this methodology prioritizes the quality, diversity, and ethical considerations surrounding data. By delving into the significance of data in developing intelligent systems, we can uncover the immense potential it holds to drive AI advancements and create more robust and responsible applications.
The Role of Data in Machine Learning
The role of data in Machine Learning is absolutely fundamental, as it serves as the cornerstone upon which intelligent systems are built. Data fuels the learning process, enabling machine learning models to extract patterns, relationships, and insights from examples in the data. The data’s quality, quantity, and diversity directly influence the model’s performance, generalization ability, and the accuracy of its predictions. A large, representative, and well-curated dataset is essential for training robust models that can handle real-world challenges effectively.
Furthermore, data acts as the ground truth for supervised learning, where models learn from labeled examples to make predictions on new, unseen data. Data labeling and annotation are essential tasks in this context, guiding the model to understand the mapping between input features and their corresponding output labels or annotations. Through data labeling, machine learning models acquire knowledge and can subsequently make informed decisions, recognizing patterns and making predictions in domains ranging from natural language processing to computer vision and beyond.
To harness the full potential of Machine Learning, practitioners and researchers must prioritize data quality, ethical considerations, and responsible data handling practices. Understanding the role of data empowers us to develop more reliable and impactful AI applications, ensuring that the models we build are not only accurate but also aligned with the values and needs of society. As data-driven technologies continue to shape the world, a data-centric mindset will lead us to innovations that transform industries, enhance decision-making, and address some of humanity’s most pressing challenges.
Data Collection and Preprocessing
Data collection is the pivotal initial phase in data-centric Machine Learning. The objective is to obtain a relevant, diverse, and comprehensive dataset that represents the problem domain accurately. The data sources include databases, APIs, web scraping, sensor networks, or user-generated content. In some cases, data might already be available in well-structured formats; in others, extensive effort is required to gather and organize the data.
Handling Missing Values
Missing values are a common occurrence in datasets and can significantly impact the performance of machine-learning models. Imputation is the process of filling in these missing values with estimated or calculated values. Scikit-learn provides the SimpleImputer class to handle missing values using various strategies, such as mean, median, most frequent, or constant.
# Importing Scikit-learn from sklearn.impute import SimpleImputer # Handling missing values using mean imputation imputer = SimpleImputer(strategy='mean') data_filled = imputer.fit_transform(data) # Handling missing values using median imputation imputer_median = SimpleImputer(strategy='median') data_filled_median = imputer_median.fit_transform(data) # Handling missing values using most frequent imputation imputer_mode = SimpleImputer(strategy='most_frequent') data_filled_mode = imputer_mode.fit_transform(data)
Normalizing Features
Features in the dataset may have different scales, which can lead to issues during model training, particularly for algorithms sensitive to scale. Normalization is the process of transforming features to bring them to a common scale, often ranging between 0 and 1. Scikit-learn provides the StandardScaler class for this purpose.
# Importing Scikit-learn from sklearn.preprocessing import StandardScaler # Normalize features using StandardScaler scaler = StandardScaler() data_normalized = scaler.fit_transform(data_filled)
These preprocessing steps are typically performed in sequence. First, missing values are imputed using a chosen strategy. Then, the data is normalized using the StandardScaler or other appropriate scaling methods. This sequence ensures the data is complete and features are on a consistent scale, preparing it for training machine learning models.
It’s important to note that preprocessing steps like imputation and normalization should be fit on the training data and applied consistently to both the training and testing datasets to avoid data leakage and ensure fair evaluation of model performance. By incorporating these preprocessing techniques, we can enhance the dataset’s quality and improve the effectiveness of machine learning models.
Data Labeling and Annotation
Supervised learning involves training ML models on labeled data, where input samples are associated with corresponding output labels. Data labeling and annotation play a pivotal role in the success of supervised machine learning, where models learn from labeled examples to make predictions on new, unseen data. These processes involve providing the essential context and meaning to the data, enabling the model to understand the relationship between input features and their corresponding output labels. Properly labeled and annotated data is crucial in training accurate and reliable models that can generalize well to real-world scenarios.
Data labeling involves assigning categorical or numerical labels to each data instance, representing the target variable for supervised learning. In Python, Pandas is a popular library for data manipulation and labeling. For instance, consider a dataset of images with corresponding labels for different objects:
import pandas as pd
# Sample dataset
data = {
'Image': ['image1.jpg', 'image2.jpg', 'image3.jpg'],
'Label': ['cat', 'dog', 'cat']
}
# Create a DataFrame
df = pd.DataFrame(data)
print(df)
Data annotation goes beyond labeling and involves adding detailed information or annotations to specific parts of the data. This is commonly used in computer vision tasks like object detection or semantic segmentation. For instance, consider annotating regions of interest in an image:
# Assuming we have an image 'img' and corresponding bounding box coordinates x_min, y_min, x_max, y_max = 100, 50, 300, 250 # Draw bounding box on the image using OpenCV import cv2 annotated_img = cv2.rectangle(img, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2)
Data Augmentation and Synthesis
Data augmentation and synthesis are powerful techniques used to address data scarcity and enhance the performance and generalization of machine learning models. These methods aim to augment the existing dataset by creating additional variations of the data or generate entirely new synthetic data, thereby increasing the diversity and richness of the training data. By exposing the model to a broader range of data instances, data augmentation and synthesis enable it to learn more robust and representative patterns, improving its ability to handle real-world challenges effectively.
Data augmentation involves applying various transformations or modifications to existing data instances, creating new variants that retain the same label or category. In image data, augmentation techniques can include rotation, flipping, scaling, translation, brightness adjustments, and more. In Python, the “imgaug” library provides a wide range of augmentation functions:
# Data augmentation using imgaug library
import imgaug.augmenters as iaa
import cv2
# Sample image
image = cv2.imread('image.jpg')
# Augmentation pipeline
augmentation_pipeline = iaa.Sequential([
iaa.Fliplr(0.5), # Horizontal flips
iaa.Affine(rotate=(-20, 20)) # Rotations
])
# Apply augmentation to the image
augmented_image = augmentation_pipeline(image=image)
Data synthesis involves generating entirely new data instances, often using generative models like Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs). Data synthesis is particularly useful when a limited amount of real-world data is available or when collecting more data is costly or impractical. These synthetic data samples augment the training dataset, helping the model learn from a more diverse set of examples. GANs, for example, learn to generate data that closely resembles the original data distribution, creating new data points that are statistically similar to the real data:
# Data synthesis using GANs
# Code snippet for illustration purposes; actual GAN training requires more complex implementation
from keras.models import Sequential
from keras.layers import Dense, LeakyReLU, BatchNormalization
# Define GAN architecture
generator = Sequential([
Dense(256, input_shape=(100,)),
LeakyReLU(alpha=0.01),
BatchNormalization(),
Dense(512),
LeakyReLU(alpha=0.01),
BatchNormalization(),
Dense(784, activation='tanh')
])
# Generate synthetic data using the generator
import numpy as np
latent_space = np.random.normal(size=(batch_size, 100))
synthetic_data = generator.predict(latent_space)
Challenges of Data-Centric AI
Data-Centric AI, while powerful and transformative, is not without its challenges. Here are some of the key challenges that practitioners and researchers face in the data-centric approach to machine learning:
- Data Quality and Bias: The quality of the data used for training greatly impacts the performance and fairness of machine learning models. Biased or incomplete data can lead to biased predictions, perpetuating inequalities and unfair outcomes. Ensuring data quality, mitigating bias, and addressing fairness in data representation is a critical challenge in data-centric machine learning. Read more on How to Automate Data Cleaning.
- Data Privacy and Security: As machine learning increasingly relies on vast amounts of data, concerns around data privacy and security become paramount. Aggregating and sharing sensitive data from various sources can lead to potential privacy breaches or expose sensitive information. Striking a balance between data accessibility for model training and protecting individual privacy remains a significant challenge.
- Data Imbalance: In real-world datasets, the distribution of classes or labels may be imbalanced, with some classes being significantly underrepresented. Imbalanced data can lead to models that favor the majority class and perform poorly on minority classes. Handling imbalanced data and ensuring the model learns from all classes equally is a challenge that requires specialized techniques like oversampling, undersampling, or using class-weighted approaches. Read more on the Best Practices for ML Model Training.
- Data Acquisition and Cost: Collecting high-quality and diverse datasets can be time-consuming, resource-intensive, and costly. In certain domains, obtaining labeled data may require expert annotators, adding further complexity. Balancing the cost and effort of data collection while ensuring data representativeness is a challenging trade-off.
- Data Compatibility and Integration: In real-world scenarios, data may come from multiple sources with varying formats and structures. Integrating and harmonizing disparate data can be challenging, requiring data engineers and domain experts to ensure data compatibility.
- Data Continuity and Concept Drift: In dynamic environments, data distributions may change over time due to data or concept drift. Models trained on historical data may become less accurate or outdated as new data streams in. Continuously monitoring and adapting models to evolving data patterns is a challenge in data-centric machine learning.
Coresets
Coresets are small, weighted subsets of the original input data that accurately represent the entire dataset. They are designed such that training machine learning models on coresets yields the same results as training on the complete dataset. Coresets help reduce computational costs, enable real-time model updates, avoid data drift, and facilitate faster hyperparameter optimization, making them a powerful tool in data-centric machine learning.
Using the DataHeroes library in Python (which can be installed using pip install dataheroes), a coreset can be built on a dataset using the following example code (on a dataset of 5 million samples spread across 10 classes):
from dataheroes import CoresetTreeServiceLG
# Build the coreset tree service object
service_obj = CoresetTreeServiceLG(data_params=data_params,
optimized_for='training',
n_classes=10,
n_instances=5_000_000
)
service_obj.build_from_file(train_file_path)
By leveraging coresets, data-centric AI becomes more efficient, cost-effective, and adaptive, leading to better model performance and more accurate predictions on evolving real-world data. Here are some ways coresets can help in Data-centric AI:
- Efficient Data Representation: Coresets allow the creation of a small, weighted subset of the original dataset that accurately represents the entire data distribution. By selecting only the most informative and representative data points, coresets reduce the computational and memory requirements for model training, making them more efficient and scalable, especially when dealing with large datasets.
- Reduced Model Update Time: In real-world scenarios, data is continuously evolving, and model updates are necessary to adapt to these changes. Coresets enable faster model updates by retraining the model on the small, representative subset instead of the entire dataset. This significantly reduces the time and resources required for model updates, allowing for more frequent and timely model adjustments in response to data changes.For example, to train a Logistic Regression model on the dataset we described above, you can use the coreset structure using the following code.
# Get the top level coreset (~2K samples with weights) coreset = service_obj.get_coreset() indices, X, y = coreset['data'] w = coreset['w'] # Train a logistic regression model on the coreset. coreset_model = LogisticRegression().fit(X, y, sample_weight=w) n_samples_coreset = len(y)
- Avoiding Data Drift: Data drift occurs when the data distribution changes over time, leading to performance degradation of the trained models. Coresets provide a mechanism to track and adapt to data changes efficiently, allowing for near real-time model updates and helping to avoid data drift. Read in more detail on How to Keep Your ML Model Constantly Updated.
- Hyperparameter Optimization: Coresets facilitate faster hyperparameter optimization by allowing quick model retraining on the representative subset of data. This enables practitioners to explore different hyperparameter combinations efficiently, reducing the time and resources needed for the tuning process.To perform a grid-search on the hyperparameters of the above Logistic Regression model (type of penalty, cost value, and type of solver) utilizing the existing coreset structure, the following code can be used:
# Set up the parameter grid param_grid = {'penalty': ['l1', 'l2'], 'C': [0.1, 1, 10, 100], 'Solver': ['liblinear','saga'] } # Get the best hyperparameters (and optionally the model) result = service_obj.grid_search(param_grid) - Anomaly Detection and Data Cleaning: Coresets can help identify outliers or anomalous data points in the dataset. By assigning importance values to data samples, anomalies can be detected based on their high importance scores. This property can also be used to identify potential labeling errors in the dataset, helping in data cleaning and enhancing the model’s reliability. Read about the 5 Important Data Cleaning Techniques.The DataHeroes Coreset library, at its build phase, computes an “Importance” metric for each data sample, which can help fix mislabeling errors, thus validating the dataset. For example, one can identify samples with very high “importance” values, i.e., samples that are out of the ordinary for that class distribution and potentially anomalies.Once the importance samples are identified, you can remove them from the coreset if they are anomalous. The following code achieves this:
# Get the top `num_images_to_view` most important samples num_samples_to_view = 500 service.get_cleaning_samples(class_size={of_interest_class_id: "all"}) important_sample_indices = result["idx"][:num_samples_to_view] important_sample_values = result["importance"][:num_samples_to_view] # Removing `idxes_to_delete` samples indices stored in `important_sample_indices` from the Coreset idxes_to_delete = important_sample_indices[:200] #Example service_obj.remove_samples(idxes_to_delete) # Re-evaluate the AUROC score for the cleaned dataset sample_weights[idxes_to_delete] = 0 new_score = eval_lg_cv(sample_weights=new_weights) - Enabling Iterative Model Refinement: Coresets allow for iterative and interactive model refinement. By updating the coreset with new data samples or making changes to existing samples, models can be retrained quickly and efficiently, enabling multiple iterations of model improvement in a short time.Read the case study on the NYC Taxi dataset for iterative model refinement with coresets.
- Cost-Efficient Machine Learning: With coresets, the computational cost of training and retraining models is significantly reduced. This cost-efficiency makes it practical to update machine learning models as frequently as needed, leading to more responsive and adaptive AI systems.For example, on the NYC Taxi dataset from this case study, the comparison of the CO2 emissions and the total retraining time by retraining a model with the entire dataset and retraining on coresets is shown below. Clearly, on every retraining job, the time required to train a coreset is much lower.
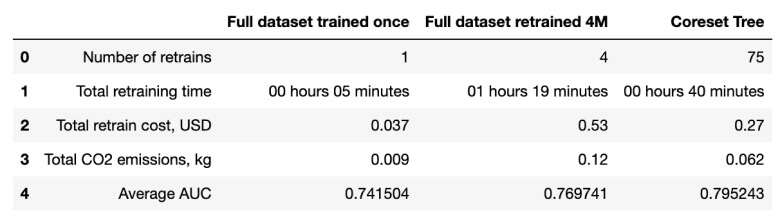
Training time for NYC Taxi Dataset
Conclusion
In conclusion, data-centric AI has emerged as a transformative approach, placing data at the heart of AI development. The power of data in machine learning cannot be understated, as it lays the foundation for building accurate, reliable, and efficient models. From data collection and preprocessing to labeling, annotation, and augmentation, each step plays a crucial role in shaping the success of machine learning endeavors.
Furthermore, introducing coresets into the data-centric landscape offers an exciting frontier for more efficient and cost-effective model training. Coresets allow us to create small, weighted subsets of data that accurately capture the essence of the entire dataset, enabling model updates in near real-time and mitigating the challenges posed by data drift. Through coresets, hyperparameter tuning becomes a more agile process, and iterative model refinement becomes feasible without the computational burden of training on the complete dataset.




{kind=link}