
In the world of machine learning, building a powerful and accurate model is just the first step. As models are deployed in real-world scenarios, they require ongoing maintenance to ensure they continue to deliver reliable results and adapt to changing environments. Model maintenance is an essential aspect of the machine learning lifecycle that encompasses monitoring, updating, and optimizing models to sustain their performance and longevity.
Why is it important?
Maintaining a model is vital for preserving accuracy, adapting to evolving data, addressing concept drift, and detecting and fixing model degradation.
- Preserving accuracy and performance: Over time, models may experience a decline in performance due to changes in the underlying data or the environment in which they operate. Regular maintenance helps identify and rectify any performance degradation to ensure the model continues to provide reliable predictions.
- Adapting to evolving data: Data is not static, and models must be able to adapt to changes in the data distribution. By monitoring the data and updating the model accordingly, it can remain effective even as the underlying data evolves.
- Addressing concept drift: Concept drift occurs when the relationship between input features and the target variable changes over time. Maintenance involves detecting and handling concept drift to ensure the model remains accurate and up to date.
- Detecting and fixing model degradation: Models can degrade over time due to changes in the underlying data or changes in the system on which they are deployed. Regular maintenance allows for the detection of such degradation and provides opportunities to fix and improve the model.
Bottleneck of Model Maintenance
Model maintenance poses several challenges, with time and cost being significant factors that organizations need to address.
Let’s explore these challenges in more detail:
- Time-intensive retraining: Retraining models can be a time-consuming process. As models are updated with new data or undergo concept drift, retraining is necessary to ensure optimal performance. However, training complex models on large datasets can take hours, days, or even weeks, depending on the computational resources available.
For example, training deep learning models with millions of parameters on extensive datasets can require significant computational time, making frequent retraining impractical.
Training the model even once can be challenging if proper protocols are not followed, leading to suboptimal performance. Read this guide to learn the best practices for model training in machine learning. - Cost of computational resources: Model maintenance often involves substantial computational resources, such as cloud infrastructure or specialized hardware. The cost of running and scaling these resources can be significant, particularly when retraining is required multiple times to accommodate evolving data or performance improvements.
For instance, utilizing powerful GPUs or dedicated computing clusters for training and retraining models can result in substantial expenses, especially if the process needs to be repeated frequently. - Data collection and labeling: Maintaining accurate and up-to-date models relies on collecting and labeling new data. This process can be time-consuming and resource-intensive, as it involves data acquisition, annotation, and quality assurance. Additionally, obtaining labeled data for specific domains or niche applications may require specialized expertise and can further increase costs.Gathering labeled data for tasks such as image recognition or natural language processing often requires human annotators, which adds to the overall time and expense of model maintenance. However, knowing the techniques for automated detection and correction of anomalous data can help mitigate this issue.
- Balancing model performance and resource constraints: Organizations must strike a balance between achieving optimal model performance and working within resource constraints. While more extensive datasets and complex models may improve accuracy, they also increase computational requirements, making maintenance more challenging and expensive.
Striking the right balance is crucial, as organizations must consider the trade-offs between accuracy, computational resources, and the desired frequency of model updates to effectively manage maintenance costs.
The Solution: Coresets
Coresets refer to a sampling methodology originating in computational geometry used to approximate optimization problems. They are based on selecting a subset of the original dataset that maintains the entire dataset’s statistical properties (including the corner cases). Training a model on the Coreset should give the same result as training it on the full dataset.
Moreover, the DataHeroes library can be used to create and manage a more complex structure known as a Coreset Tree, which can be used to perform different operations such as training a model, updating data labels, or removing unnecessary samples. The Coreset Tree is a powerful structure because it comprises multiple Coresets, each built separately using a chunk of the dataset. These independent structures are then combined iteratively to form the final tree-like structure.
There are several advantages to using the Coreset Tree versus a single Coreset, primarily related to the reduced computation time for building and updating the tree over time. Together, these features make it a great candidate structure for model maintenance in production. Finally, using the Coreset tree reduces the training time significantly, allowing data scientists to retrain more often, test a larger variety of models, and keep the model updated with the latest data.
By leveraging coresets, organizations can save time, reduce costs, and minimize CO2 emissions associated with model maintenance activities. As machine learning continues to expand across industries, embracing efficient techniques like coresets is crucial for streamlining operations, optimizing resource utilization, and fostering environmental responsibility.
NYC Taxi: A Case Study
To further illustrate the challenges and potential solutions in model maintenance, we conducted a case study using the NYC Taxi dataset. In this study, we deliberately introduced concept drift into the dataset, simulating a real production scenario. Our objective was to compare the traditional approach of training a model on the entire dataset with the usage of coresets for more efficient model maintenance.
We introduced drift into the dataset starting from the 8Mth sample. This allowed us to simulate a real production scenario, where the model (a Logistic Regression model) was initially trained on the first 2 million samples (before the drift occurred) using two different methods: 1) standard `sklearn` fit function on the entire dataset, and 2) `dataheroes` by creating a Coreset and training the model on the Coreset.
We define the following constraints for the models:
# Define constants
parameters = {
'train_full_model': True,
'evaluation_metric': 'AUC',
'n_training_size_count': 2_000_000,# number of samples to use for initial training
'n_streaming_size': 17_000_000, # number of samples for streaming
'dataset_filepath': 'data/2020_Yellow_Taxi_Trip_Data_Drift_8M.hdf5', # path to the Yellow Taxi Trip data file
'n_samples_per_round': 200_000, # number of samples per batch
'n_samples_per_round_delayed': 4_000_000, # retrain full model every 20 batches = 20 * 200_000
'hour_cost': 0.4, # AWS EC2 On-demand pricing for m4.2xlarge
'co2_hour_per_kg': 0.0925,
'model_params': {
'max_iter': 10000,
'random_state': 42,
'C': 100,
'tol': 1e-6
},
'coreset_params': {
'tree_level': 1,
'coreset_size': 40_000,
'chunk_size': 200_000
}
}
features = [
'passenger_count',
'trip_distance',
'total_amount',
'label_encoded_PULocationID',
'label_encoded_DOLocationID',
'label_encoded_RatecodeID',
'label_encoded_store_and_fwd_flag',
'label_encoded_payment_type'
]
target = 'target'
Training on the Most Recent Data
To simulate real-life scenarios where model updates need to be performed frequently, we retrained the models at regular intervals as new data became available. Since training on the full dataset is time-consuming, we only performed full dataset retraining every 4 million samples (2M, 6M, 10M, 14M). In contrast, the coreset approach enabled faster model updates, as retraining on the Coreset was much quicker (approximately 30 seconds, including the time to rebuild the tree using the new batch of 200K samples). We retrained the coreset-based model at intervals of 200K samples (2M, 2.2M, 2.4M, 2.6M, etc.) to mirror the incremental nature of real-world data accumulation.
To build the Coreset tree structure, we need only a couple of lines of code as the following:
from dataheroes import CoresetTreeServiceLG # Initialise and build tree tree = CoresetTreeServiceLG(coreset_size=parameters['coreset_params']['coreset_size'], optimized_for='training') time_build_start = time() tree = tree.build(X_train, y_train, chunk_size=parameters['coreset_params']['chunk_size'])
The time to build this tree structure was only 7.61 seconds. Now, to train this Coreset tree, we use the following code.
coreset_model = LogisticRegression(**parameters['model_params']) time_train_start = time() coreset_model = tree.fit(level=parameters['coreset_params']['tree_level'], model=coreset_model)
The time to train the Coreset tree model (built on the initial 2M samples) is only 18.35 seconds. In comparison, the time to train the model on the full dataset (i.e., all 2M samples) was 335 seconds. Both the full dataset model and the coreset tree achieved an AUC (area under ROC curve) score of around 0.83. Thus, the coreset structure was able to select a representative subset of the 2M samples, allowing it to retain performance while decreasing computation time drastically.
Benefits of Coreset Sampling
Our experiment demonstrated several advantages of using Coreset sampling in the context of data drift management:
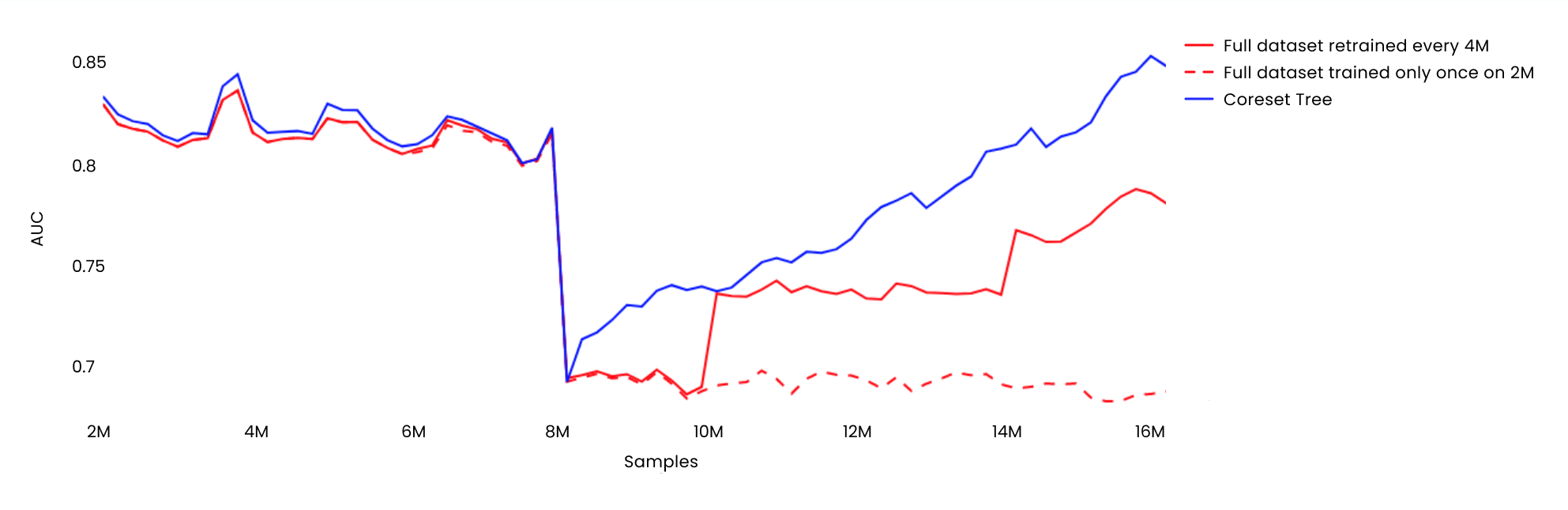
- Faster Recovery: The coreset-based model exhibited faster recovery from data drift than the model trained on the full dataset. By training on the first 2 million samples and then retraining on a new batch of samples, the coreset approach aligned more closely with real-world practices, enabling quicker adaptation to changing data distributions.

Performance of Coreset in terms of AUC on a dataset with drift.The red dotted line indicates the performance of the model that has been trained only once with the initial 2M samples. As new data became available, this model was only tested on the dataset, and no retraining was performed.
The red solid line indicates the performance of the model that, after being trained on the same initial 2M samples, is retrained every time 4M new samples become available.
The blue solid line is the Coreset tree model’s performance which, after being trained on the same initial 2M samples, is retrained every 200K new samples. Compared to the other two models, there is a sharp improvement in performance with the coreset tree model.
- Improved Accuracy: The Coreset-based model consistently outperformed the model trained on the full dataset in terms of accuracy, as shown in the figure above. By training more frequently, the Coreset approach leveraged up-to-date information, resulting in better predictions and reduced performance degradation caused by outdated training data.
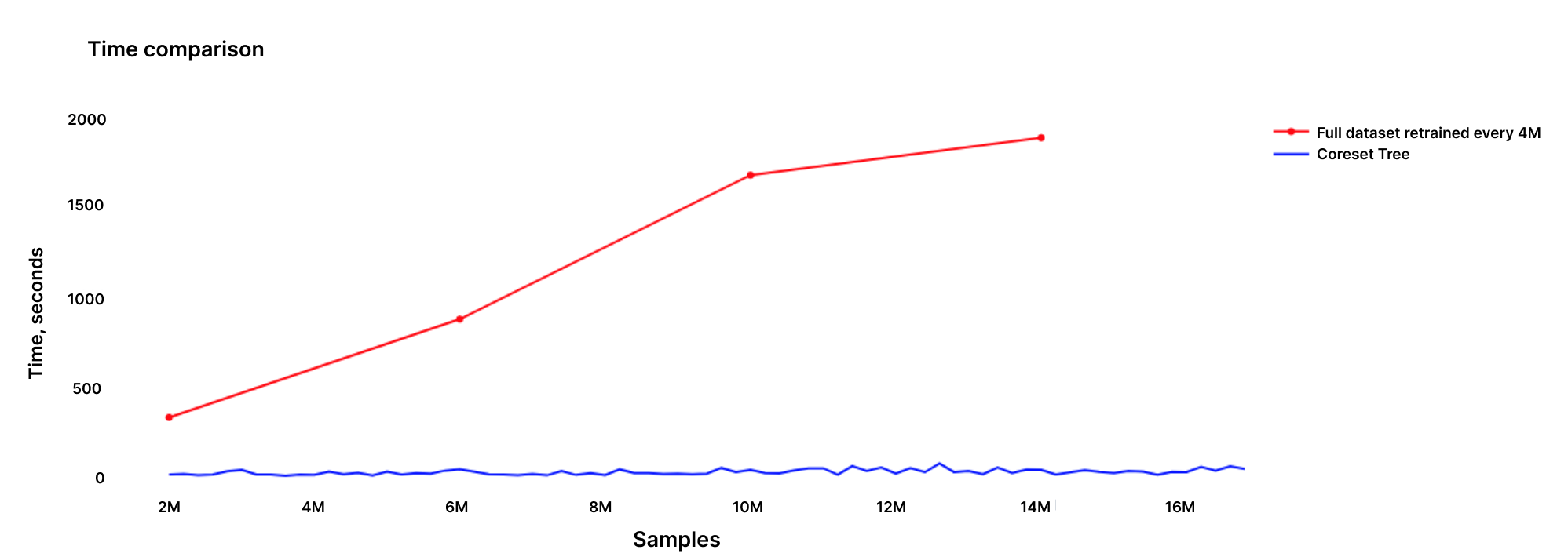
- Reduced Compute Costs: The compute time to train the full dataset and to update and train the Coreset tree every time is shown in the graph below. With more samples, the gap between the Coreset training and the full dataset training kept increasing. The training time of the full dataset model, as more data was added, increased linearly, while the training time for the coreset model, even with new added data, remained approximately the same.

Comparison of training time for the coresets and the full dataset
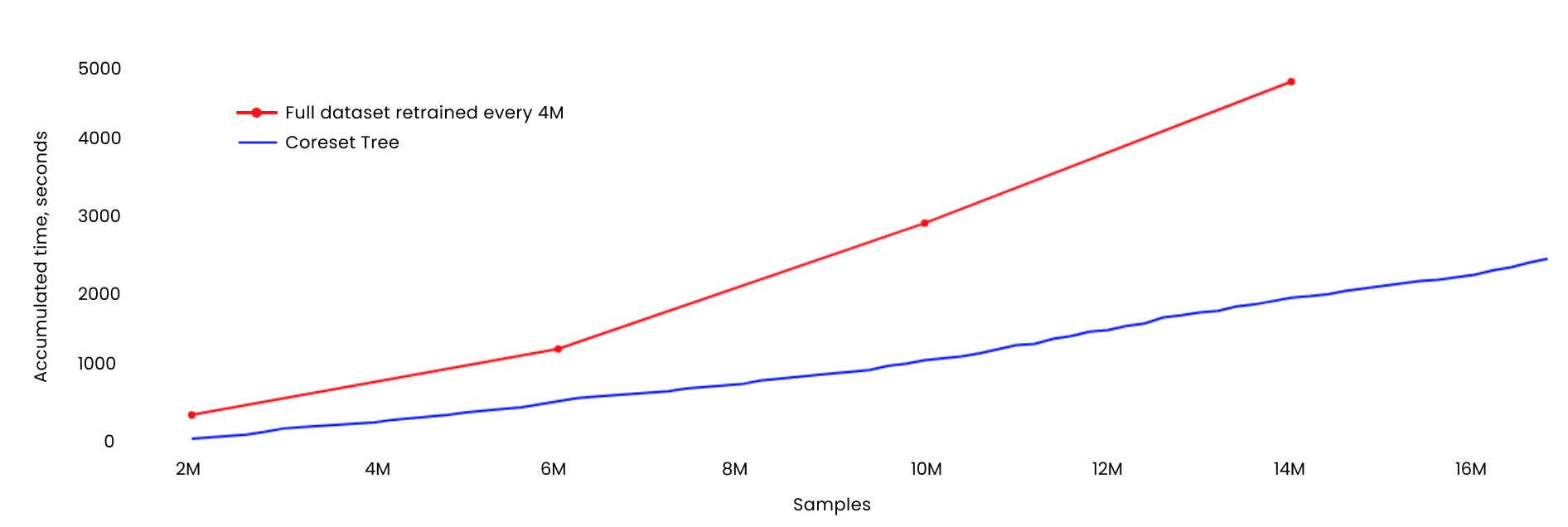
Despite training more frequently, the cumulative training time of the Coreset-based model (retrained every 200K samples) was significantly lower compared to the full dataset approach (retrained every 4M samples), as shown in the figure below. This translates to reduced computational resource requirements and cost savings, making Coreset sampling an appealing solution in terms of both efficiency and economy.

Cumulative time for training coresets vs. the full dataset
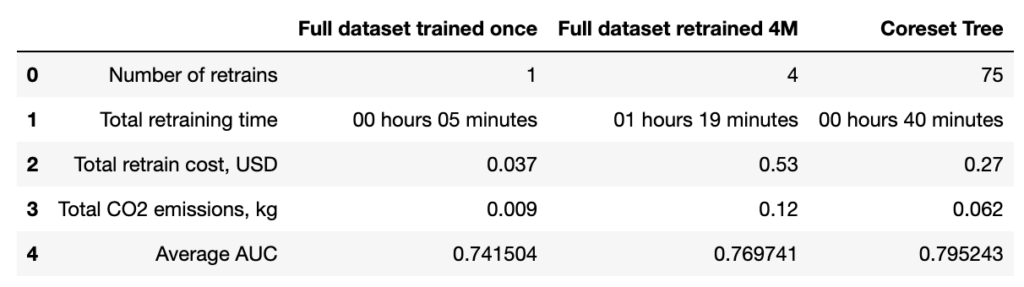
- Reduced CO2 emissions: The quantitative metrics for training the entire dataset once with 2M samples, retraining the model every 4M new samples, and retraining the Coreset tree structure every 200K new samples are shown below. The CO2 emissions for the full dataset trained once seem to be the lowest, but when considering CO2 emission per training iteration, the coreset tree structure has a much more environment-friendly emission rate (0.0008 kg/training- 10 times lower than the full dataset trained once).

Conclusion
Model maintenance is not only about preserving accuracy but also optimizing efficiency, cost-effectiveness, and environmental sustainability. Incorporating Coresets into model maintenance workflows can revolutionize the process by reducing computational requirements while maintaining performance.
Coresets are a powerful sampling technique that can reduce the training time of ML models while preserving the model’s accuracy. They have the potential to help data scientists identify labeling errors and other data-related issues, resulting in more reliable and accurate models.

