Automated Framework for ML Training Set Sampling, Optimization and Refinement
DataHeroes improves ML model quality by up to 25% by using state-of-the-art data sampling techniques and automated processes for iteratively sampling, refining and optimizing your training dataset
Automated Framework for ML Training Set Optimization and Refinement
DataHeroes improves ML model quality by up to 25% by using state-of-the-art data sampling techniques and automated processes for iteratively sampling, refining and optimizing your training dataset

“AI Fund is excited to join the investment round in DataHeroes, and support Oren, Eitan, Liran and the team to bring coresets to the data science community.”

CEO at AI Fund

State-of-the-art Data Sampling
DataHeroes uses coresets – compact geometric representations that preserve key properties of the full dataset, to represent the full training dataset. By using coresets, DataHeroes can reduce noise and remove redundancies from the training dataset without affecting data distributions, resulting in a smaller dataset that is easier and faster to model.
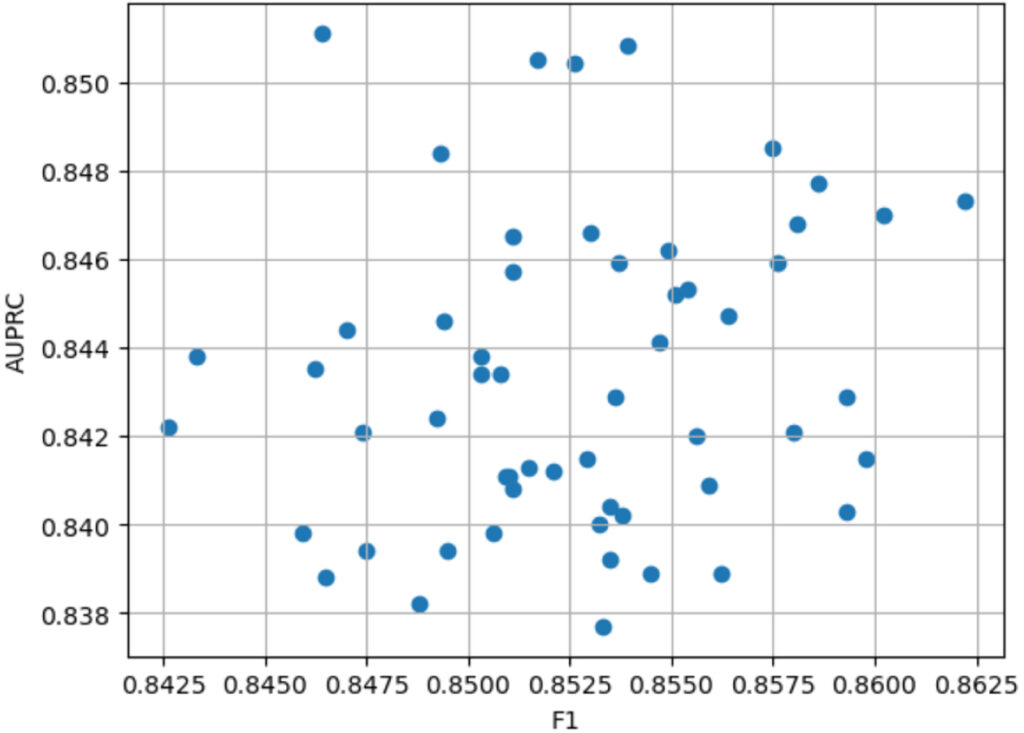
Intelligent Data Tuning
Data tuning adds a new dimension to ML model optimization by optimizing the training dataset. By creating and evaluating multiple coresets with distinct characteristics such as different class balance, weights and outlier inclusion, data tuning can be used to create a higher quality training dataset.
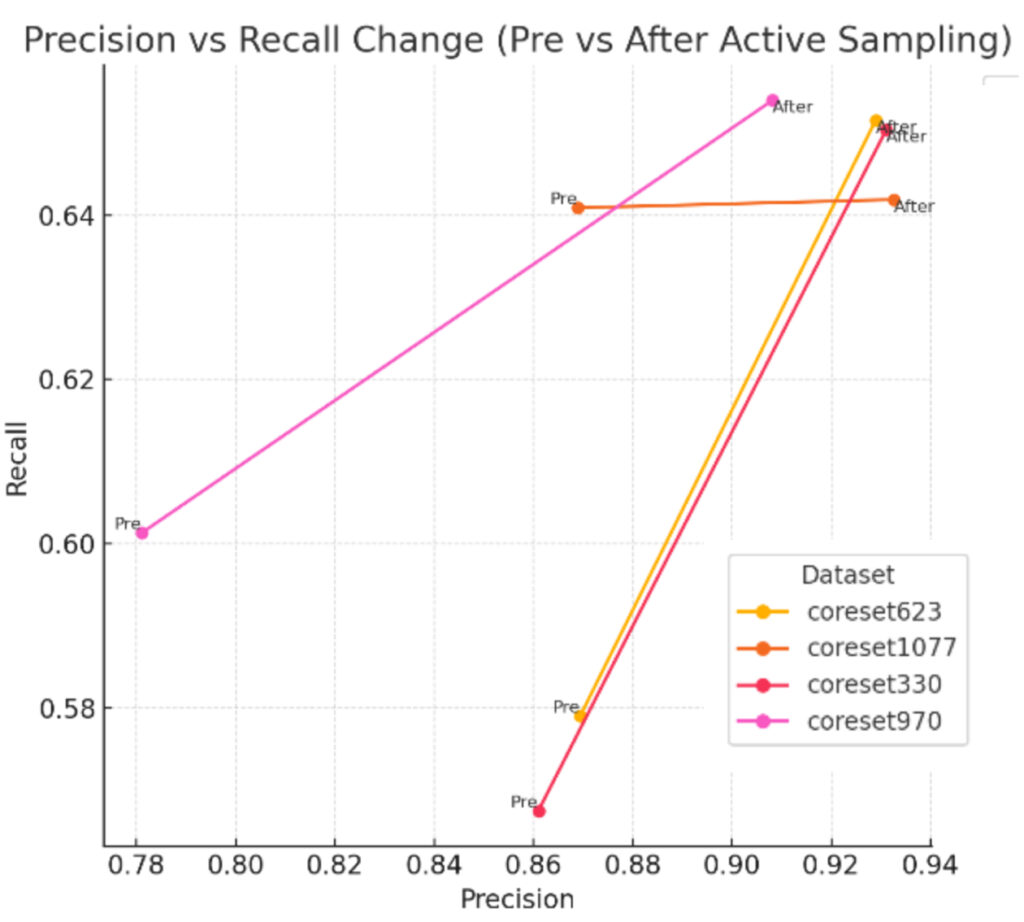
Refinement using Active Sampling
Refine and improve any coreset subsample through an automated active sampling process that iteratively evaluates the model, identifies its weaknesses and adds observations from the full training set to address the weaknesses until the optimal model is found.

Blazing Fast
Hyperparameter Tuning
Run blazing fast hyperparameter tuning and cross validation using DataHeroes unique coreset tree structure to evaluate many hyperparameter combinations and find the optimal hyperparameters for your model.

Built-in Incremental Training
Incremental Training leverages coreset trees to allow you to update your model in record speed as frequently or infrequently as necessary. Unlike online learning, incremental Training can be applied to any model, including tree-based models.
Seamlessly Move Between Clouds, Platforms and IDEs
DataHeroes allows you to maintain a consistent code base across all environments and seamlessly move between platforms, clouds and IDEs, and easily scale from your local computer to a cluster in the cloud with no code changes.