Introduction to Coresets
Introduction to Coresets: Motivation & Coresets
Introduction to Coresets: How to Compute a Coreset?
Introduction to Coresets: Applications
Motivation & Coresets
Big Data is a catchy buzzword nowadays. You may hear it in many conversations on trending topics, such as deep learning (DL), machine learning (ML), robotics, and more. Notably, the gains of machine learning have come at the expense of ever-larger and more complicated models trained on vast volumes of datasets. In fact, many recent advancements in ML have been made possible by the sheer size of the training data.

Well, the answer to this question depends on the scenario at hand:

Limited Hardware

Limited Time
New computation models
In addition to the previously detailed cases, sometimes, Big data is actually big! Every day, 2.5 exabytes of data (2.5× 1018) is generated by a large number of information-sensing mobile devices, remote sensing, software logs, cameras, forums, microphones, RFID readers, wireless sensor networks, and more.
Thus, such a massive amount of data created every day may be considered infinite data, requiring supporting new computation models:

The streaming model

The distributed model
Mislabeled input data
Even if we can handle this massive data under these computation models, usually, the usage of these large datasets requires human interaction. For example, although there are billions of images of cats and dogs across the web, to use them for training a machine learning model to classify an input image whether it is a cat or a dog, we still need to label these images first. Typically, data labeling begins by asking humans (or even experts) to make judgments on each item from the unlabeled data. In our example, labelers are requested to tag all images by answering the question “Is it a photo of a cat or a dog?”.
Dealing with a huge dataset raises a big possibility of human mistakes while labeling the images. These mistakes are translated into mislabeled input data, which may harm the performance of the desired ML algorithm. Hence, data scientists are required to identify mislabeled input items before applying the machine learning algorithm to the incorrectly labeled data, in order to obtain a solution that reflects the real world.
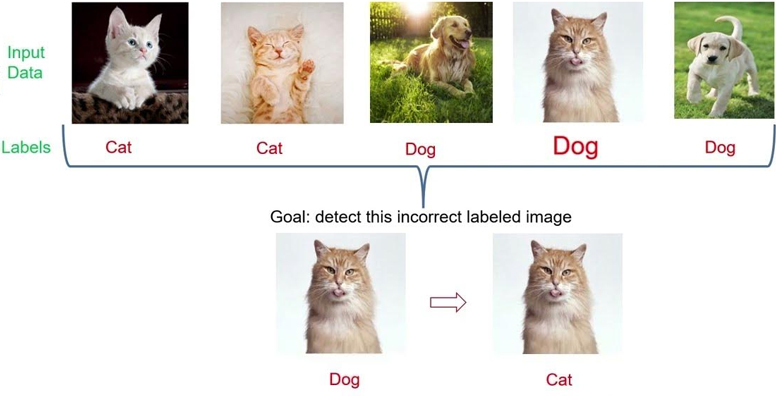
Data quality
Even when the data is correctly labeled, data scientists are interested in identifying important (high-quality) images. If we are dealing with a classification problem for dogs or cows, and we are given the following data set:

We can observe that the 4th image is very weird, as it is very strange to see a cow indoors. Hence this image is either (i) very important as it is one of a kind, and in this case, we should focus on such an image when we train our model to make sure we classify it correctly, or (ii) should be removed as it does not reflect the usual cases, and we do not want our model to take this image into consideration.
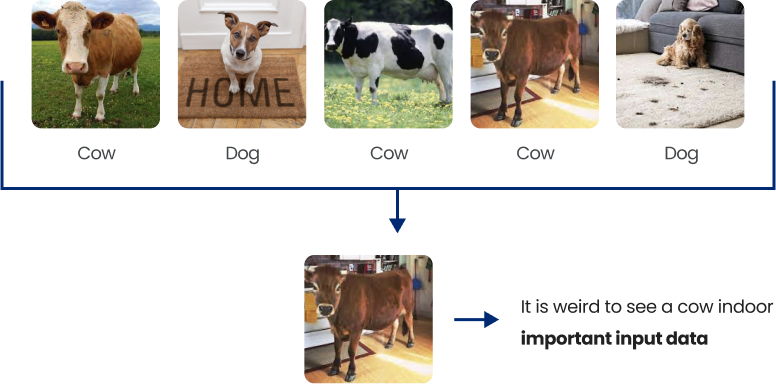
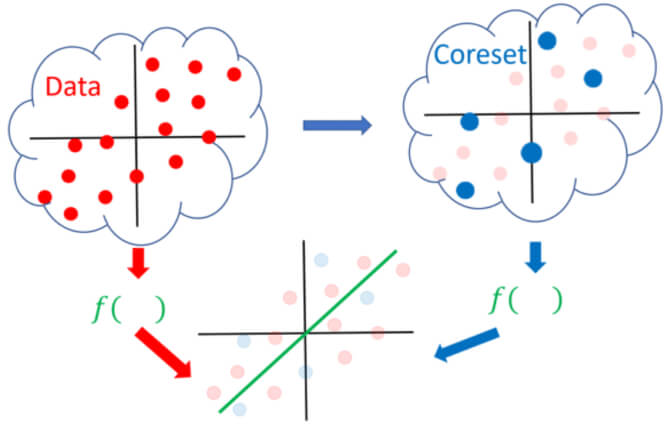
Coresets
A common practical and theoretically supported approach for solving the above challenges is called “coreset”. Coresets have been getting increased attention during the past year. Informally, a coreset is (usually) a small, weighted subset of the original input set of items, such that solving the problem on the coreset will yield the same solution as solving the problem on the original big data.
Defining a problem
To formally define and build coresets for a machine learning problem, first, we need to formally define all the ingredients required to form a machine learning problem. We now give the basic three ingredients to define an optimization problem:
- The input data (denoted by
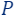 ): this is the input (usually large) dataset, which we are interested in optimizing some cost function with respect to it.
): this is the input (usually large) dataset, which we are interested in optimizing some cost function with respect to it. - The query set (denoted by
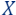 ): this is the set of all possible candidate solutions/models, where usually the goal of ML, is to output a model from this set, which minimizes the desired cost function with respect to the input data.
): this is the set of all possible candidate solutions/models, where usually the goal of ML, is to output a model from this set, which minimizes the desired cost function with respect to the input data. - The cost function
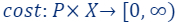 we wish to optimize.
we wish to optimize.
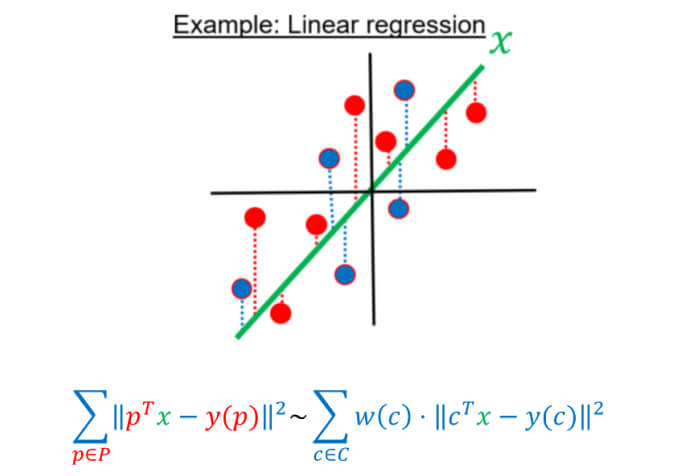
These three ingredients, formally define the optimization problem at hand. For example, in linear regression:
- The input data is a set
 and their label function
and their label function 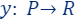 (red points in the figure).
(red points in the figure). - The query set is the set of every vector in
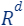 (the green line is an example of a query/candidate solution).
(the green line is an example of a query/candidate solution). - The cost function we wish to minimize is
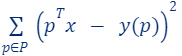 .
.
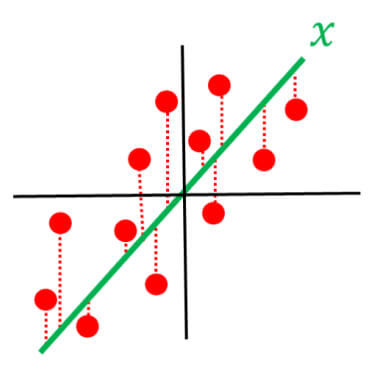
Defining a coreset
Given all the ingredient which defines/forms an optimization problem, i.e.,
- Let be an input set.
- Let be the query set – the set of candidate solutions.
- Let be a cost function.
Then, a coreset is a pair 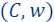 where
where  and
and 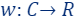 such that for every query
such that for every query 
 .
.
Coresets Properties
Coreset has many interesting properties other than approximating the optimal solution of the original big data. In this article, we will summarize only three properties of coresets:
-
A coreset
for an input data approximates the loss of the with respect to any query (candidate solution) and not only the optimal one, i.e., for every  . This is very important to support streaming data and to show that optimal solutions, approximated solutions, or even heuristics on the coreset yields a good result on the full data.
. This is very important to support streaming data and to show that optimal solutions, approximated solutions, or even heuristics on the coreset yields a good result on the full data.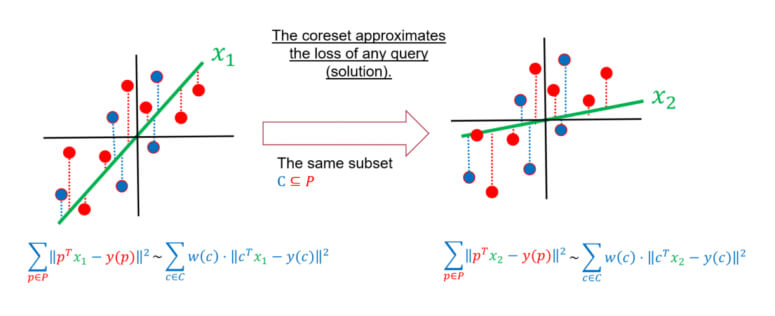
-
A union of coresets is a coreset. Assume you are given a set
that was partitioned into 5 subsets 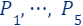 . For each of these subsets, we computed coreset, i.e., for every set
. For each of these subsets, we computed coreset, i.e., for every set 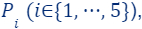 we have computed its own coreset
we have computed its own coreset 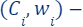 which satisfies for every
which satisfies for every 
Define the set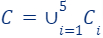 and the weights function
and the weights function 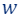 as the union of the five weight functions, we get that is a coreset for , i.e., for every
as the union of the five weight functions, we get that is a coreset for , i.e., for every 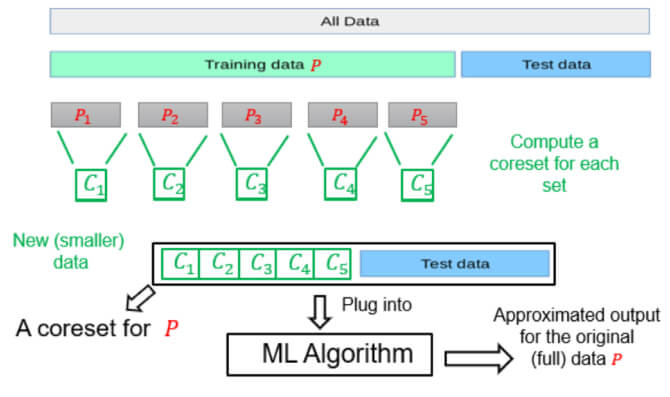
-
Coreset of a Coreset is a Coreset. Recall the set
which is a coreset for the input data . We can further compute a coreset (once more) for to obtain a new smaller coreset 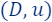 . Now, for every
. Now, for every  and
and
Thus,
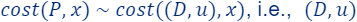 is a (smaller) coreset for . We note that now the approximation error of is larger than the one of , as we computed a coreset for a coreset.
is a (smaller) coreset for . We note that now the approximation error of is larger than the one of , as we computed a coreset for a coreset.
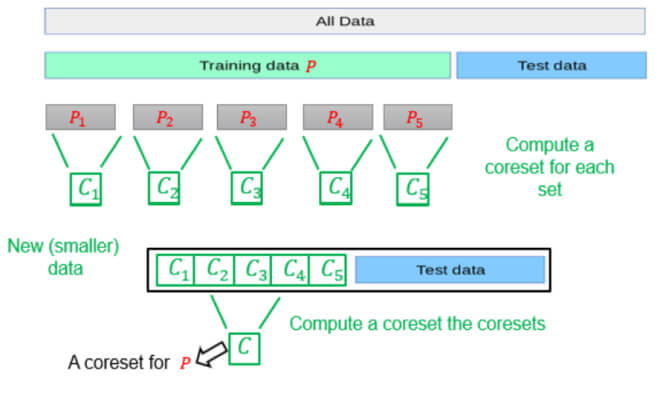
How to Compute a Coreset?
So now we understand that coreset is a kind of data summarization that gives a very strong approximation of the original data. But how can we compute a coreset for a given input dataset?
There are numerous algorithms and methods for computing coresets, each is given for some ML problem. However, mainly, these techniques can be divided into two classes:
- Deterministic coresets: In this class, the algorithms which compute the coresets output a set that is guaranteed (100%) to give an approximation for the full data.
- Sampling-based coresets: In this class, the algorithms which compute the coresets output a set that with a very high probability is a coreset.
Each of these classes has its pros and cons, for example, class 2, is probabilistic and may fail occasionally, but usually, all the algorithms falling in this class are very efficient, hence, giving very quick approximations of the original data. Furthermore, to compute a sampling-based coreset we can utilize the following famous importance sampling framework (which most of the recent papers use). The framework states the following:
- Given the tuple
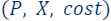 which defines our ML problem at hand.
which defines our ML problem at hand. - For every item
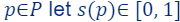 be a number defining its importance/sensitivity – we will explain how to compute it next.
be a number defining its importance/sensitivity – we will explain how to compute it next.
Once we have this defined and computed (the importance of each item in the set), the importance sampling framework applies the following simple steps to compute a coreset:
- Set
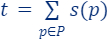 , i.e., t is the total (sum of) importance of all points.
, i.e., t is the total (sum of) importance of all points. - Build the set
 as an i.i.d Sample of
as an i.i.d Sample of  points according to
points according to 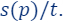 The larger the m the better the approximation error of the final coreset.
The larger the m the better the approximation error of the final coreset. - For every
 define its weight as:
define its weight as: 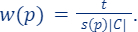
Then, with high probability, 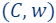 is a coreset for , i.e.,
is a coreset for , i.e.,  and , such that for every query
and , such that for every query
.
Note. The sample (coreset) size is a function of the desired approximation error, probability of failure, total sensitivity t, and another problem-dependent measure of complexity. We will provide more theoretical detail and insights in future blog posts.
But how to compute the importance 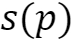 ?
?
Informally, the importance of a point/item  is defined as the maximum contribution this point gives to the loss/cost function across all possible candidate solutions, i.e., if there exists
is defined as the maximum contribution this point gives to the loss/cost function across all possible candidate solutions, i.e., if there exists  such that
such that 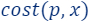 is large with respect to
is large with respect to 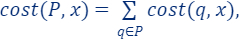 then,
then, 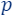 is important to the query
is important to the query 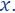
The formal definition is given as follows:
- For every :
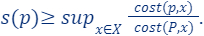
To explain the definition of sensitivity/importance let’s look at the following two cases, when 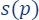 is high and when is low and see the difference between them.
is high and when is low and see the difference between them.
If 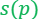 is high
is high
There exists a solution , such that affects the loss too much ( is important).
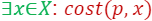 affects
affects 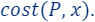
If is low
For every solution 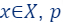 does not affect the loss, hence, it is not important.
does not affect the loss, hence, it is not important.
 does not affect
does not affect 
Hence, we sample based on this measure, as it indicates whether there exists a solution in which our point contributes to its cost, so it is considered important with respect to this solution.
Applications
Recall the original motivations for using a coreset. Now we show how coresets can be leveraged for solving the pre-discussed challenges.
Limited hardware/time
To apply our machine learning algorithm on limited hardware or in a limited time setting, we can compute a coreset for the data (e.g., via efficient sensitivity sampling framework), and then apply the old classic machine learning algorithm to the tiny coreset, to obtain a robust approximation in a faster time, using less memory, and little energy.
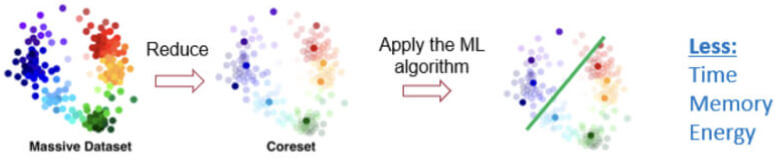
“Magically” supports the pre-discussed computational settings:
(i) streaming setting, i.e., that uses small memory and one pass over a possibly infinite input stream,
(ii) parallel/distributed setting that uses multiple threads (as in GPU), or more generally distributed data (network/cloud/AWS) via low or no communication between the machines, and even
(iii) simultaneously for an unbounded stream of data as in (i), and distributed data as in (ii).
In the streaming setting, data is received one by one or in chunk/batch style, each time a new chunk of data is received, we merge/union it with our pre-computed coreset 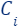 (at the beginning,
(at the beginning, 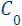 is simply an empty set). If the size of after the merge/union exceeds a predefined limit m, a coreset
is simply an empty set). If the size of after the merge/union exceeds a predefined limit m, a coreset 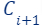 is computed for . Hence, we can maintain a small coreset for a large Big Dataset that is received in an infinite stream. Whenever we are interested in outputting a solution for the whole data seen so far, we can simply run our ML algorithm/solver on the currently maintained coreset.
is computed for . Hence, we can maintain a small coreset for a large Big Dataset that is received in an infinite stream. Whenever we are interested in outputting a solution for the whole data seen so far, we can simply run our ML algorithm/solver on the currently maintained coreset.
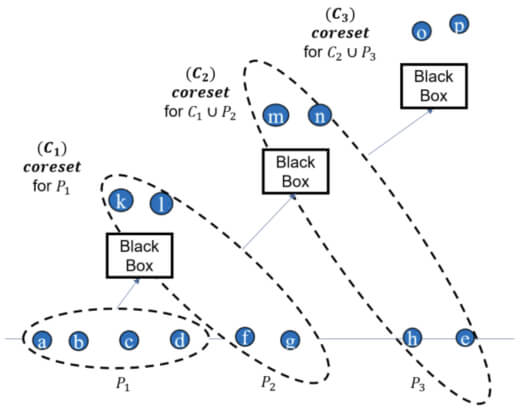
Note that here, we used property (3), i.e., the coreset of a coreset is a coreset. Also, note that as we compute more and more coresets, the approximation error gets larger and larger. To improve the approximation error in the streaming setting, we utilize the famous streaming tree (we will discuss it in another blog post; see the next figure for intuition.).
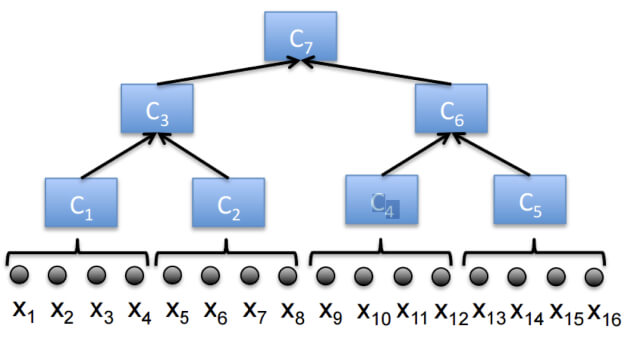
In the distributed setting, where the data is distributed across multiple machines and the goal is to compute a solution for the whole (union of the) datasets across the machines. We can compute a coreset for each dataset separately, merge (union) these coresets into one, solve the problem of the merged coreset, or even compute a new coreset for the merged coreset and then solve the problem on the result. Indeed, also here, we can utilize the streaming tree to obtain smaller approximation errors.
Identifying Incorrectly Labeled Data and High-Quality Data
Do you recall the sensitivity/importance framework, which samples points based on their importance? Let’s first recall the definition of importance:
Observe that, based on this definition, an important point is considered important because it gives a large cost/loss for a specific query, whereas other data points give little cost/loss on the same query! Meaning that other data points are “okay” with this candidate solution, e.g., classified correctly based on it, while this point is not.
This may directly indicate that:
-
This point (e.g., input image) is labeled incorrectly from the beginning, as it has a high loss whereas other points have a small loss, so intuitively if we changed its label, we may get a small loss for the same query. Hence, we can apply a smart searching algorithm based on the sensitivities/importance of the points to detect incorrectly labeled images.
-
This point (e.g., input image) is of high quality (rare to see), for example, an image may get high sensitivity/importance while it is labeled correctly, but something in it (the background, the surroundings, or even color) indicates that it should be labeled by another label, e.g., an image of a cow indoors – this is very rare.
Hence, we can apply a smart searching algorithm based on the sensitivities/importance of the points to detect important high-quality images. Consequently, these detected images are either extremely significant because they are unique, in which case we should concentrate on such images when we train our model to ensure that we classify them correctly, or (ii) we should remove some of them because they do not reflect the typical cases, and we do not want our model to take this data into account.
Coresets have many other applications, we refer the interested reader to the following surveys on coresets: Introduction to Core-sets: an Updated Survey and Overview of accurate coresets.