Coresets
A Coreset is a weighted subset of samples from a larger dataset, such that the selected samples maintain the statistical properties and outliers of the full dataset. Training or tuning an algorithm on the Coreset will yield the same results (or almost the same results) as training or tuning that same algorithm on the full dataset, but with significantly less compute resources and training time required.
Coresets are a research field in computational geometry and have been studied in academia for the past 20 years (click here to learn more about the theory and math behind coresets). Computing a Coreset requires a dataset with features and a desired cost function. Once a Coreset is computed, machine learning operations can be performed on the Coreset as a substitute for the full dataset.
Coreset Trees
Unlike a Coreset which is built over the entire dataset in one iteration, a Coreset Tree is comprised of multiple Coresets, each built separately on a chunk (batch) of the dataset and then combined iteratively in a tree-like manner.
In the illustration below, the entire dataset was split into 8 chunks of 10K instances each (X1, …, X8) and a Coreset of up to 1K samples was built for each chunk separately (C1, C2, C4, …, C12). Every pair of Coresets is then combined into a new Coreset, in a tree-like hierarchy, with the root being the minimal subset, called the root Coreset (C15).
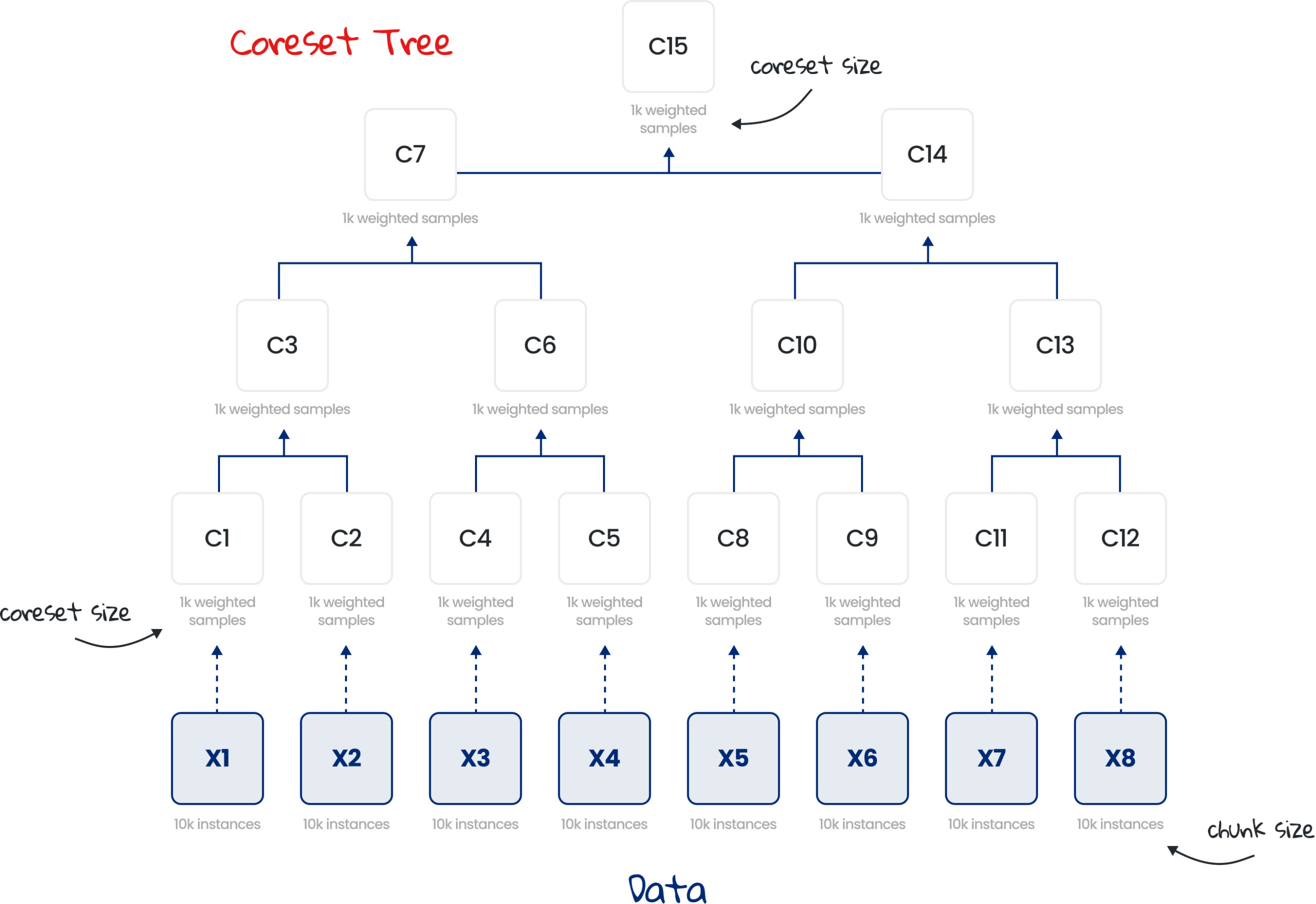
The Coreset Tree data structure has several advantages over a single Coreset:
Scale
A single Coreset requires the entire dataset to fit into the device’s memory and is therefore limited in the size of datasets it can handle. A Coreset Tree does not have this limitation as it processes the dataset in chunks and can therefore handle any dataset size by splitting the data into the appropriate chunk sizes.
Parallelization
A Coreset Tree can be computed in a distributed manner across a cluster of processors or devices, either in the same location or in multiple geographic locations.
Retraining with new data
In a Coreset Tree, additional data can be added to the original dataset without requiring re-computation of the entire Coreset Tree by adding the new data to an existing node in the Coreset Tree or computing a Coreset from the new data and adding the Coreset as a new node in the Coreset Tree. When adding data to an existing node or adding a new node, the ancestor Coresets on the path to the root Coreset need to be recomputed to keep the entire Coreset tree up to date. This feature of the Coreset Tree makes it a great fit for retraining models when new data is added, as the computational effort required to add data to the Coreset Tree is orders of magnitude smaller than retraining on the full dataset. For example, if new data is collected in production, it can be added to Coreset C12, which will require C12, C13, C14 and C15 to get re-computed, while the rest of the Coreset Tree remains unchanged.
Retraining with modified data
Similarly, updating the target or features of existing instances or removing instances, does not require recomputation of the entire Coreset Tree, as simply updating the Coreset nodes on the path to the root Coreset will suffice. E.g.: If we updated the target for some instances in X6, all we need to do to keep the Coreset Tree updated, is to update the Coresets C9, C10, C14 and C15, while the rest of the Coresets remain unchanged.
The DataHeroes library can be used to build, manage and update Coresets and Coreset Trees, and handles all the complexity behind the scenes, so that data scientists can focus on other tasks.