
Data cleaning is the process of identifying and correcting errors, inconsistencies, and incomplete information in a dataset. It involves removing duplicates, correcting misspellings, filling in missing values, and ensuring all data is formatted correctly. Data cleaning is essential because inaccurate or misleading results can be obtained if data is improperly cleaned. By cleaning the data, we aim to eliminate inconsistencies and ensure the highest quality, making it suitable for informed decision-making. Although cleaning data can take time and effort, it is essential for obtaining a clear picture of the data and making better decisions.
Problem Statement
Data cleaning involves identifying and correcting errors or inconsistencies in data. Here we consider the Titanic Dataset, which contains details of passengers on board the ship and will reveal whether they survived. It contains features like PassengerID, PClass (Passenger class), Name, Age, Sex, etc. We can automate data cleaning to improve efficiency.
Why Automate Data Cleaning
Approximately 90% of the data science life cycle is spent manually cleaning data. The data-cleaning pain point can be alleviated greatly by applying machine learning correctly. Automation can reduce the workload and save time since the cleaning process can be time-consuming and tedious. Automation can help to speed up the process, especially when dealing with large datasets. Secondly, it can help improve the cleaning process’s accuracy and consistency since automated tools can be programmed to identify specific errors and inconsistencies. This reduces the chances of human error and ensures that the data is cleaned thoroughly. Lastly, automating the cleaning process can save data analysts time to focus on other important tasks, such as data analysis and interpretation. Automating data cleaning can help increase data analysis efficiency, accuracy, and productivity.

Benefits of Automated Data Cleaning
Automated data cleaning has the following benefits:
- Reduces human error by quickly identifying and fixing errors with automated data cleaning.
- Consistent cleaning: Automated data cleaning ensures accurate results by applying the same cleaning procedures across all data sets.
- Scalability: Automated data cleaning is ideal for processing large data sets as it can handle large volumes of data.
- Customization is possible: Automated data cleaning tools can be modified to fit specific needs.
- Process automation frees up critical time by reducing repetitive manual work that can lead to human error.
- Reduces training costs: Automation reduces the need for specialist data scientists and additional expert hires.
Automated Data Preparation (ADP)
Data preparation is an important step in any project and one of the most time-consuming. The Automated Data Preparation (ADP) process cleans, transforms, and enhances raw data to automatically allow it to be used for analysis, modelling, or other data-driven functions. A data scientist or an analyst can automate tasks such as cleaning data, integrating it, engineering features, and normalizing it.
Consider a company aiming to improve its marketing strategy with customer data analysis. These data may come from social media, online surveys, or customer service records. It is important to clean and transform the data before it is analyzed. In addition to creating new variables, duplicates may need to be removed, missing values might need to be filled in, and data types might have to be converted.
By automating data preparation tools, errors can be automatically identified and corrected, data integration can be automated, and machine learning algorithms can generate new variables. Eliminating human error can save a lot of time and resources.
Data Cleaning Workflow
Automated data cleaning workflows describe how data is cleaned and processed by data cleaning tools and software. The workflow typically involves a set of predefined rules and algorithms to detect and correct errors, inconsistencies, and other issues. Workflows can be customized based on specific data-cleaning requirements.
The following steps may be included in an automated data cleaning workflow:
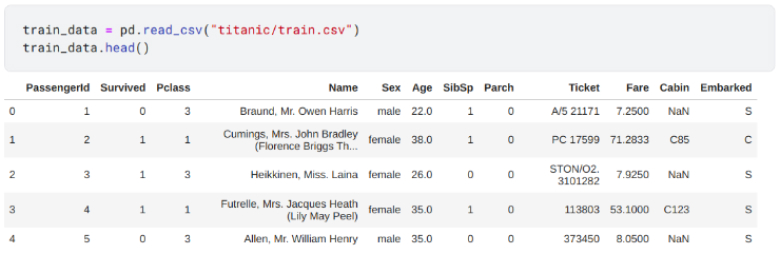
Importing Data:
Importing the dataset using pandas and creating a dataframe.
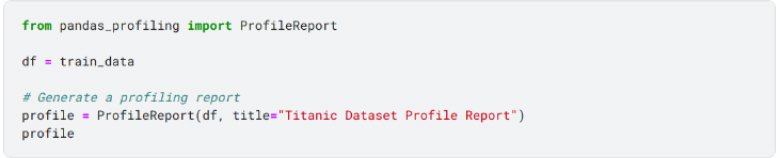
Profiling Data:
Profile the data using an automated data profiling tool. A tool like pandas profiling library can be used to perform this step.
Generated Report:
Overview of the dataset providing high-level information about the dataset, like the number of features, data type of the features, missing values, etc.
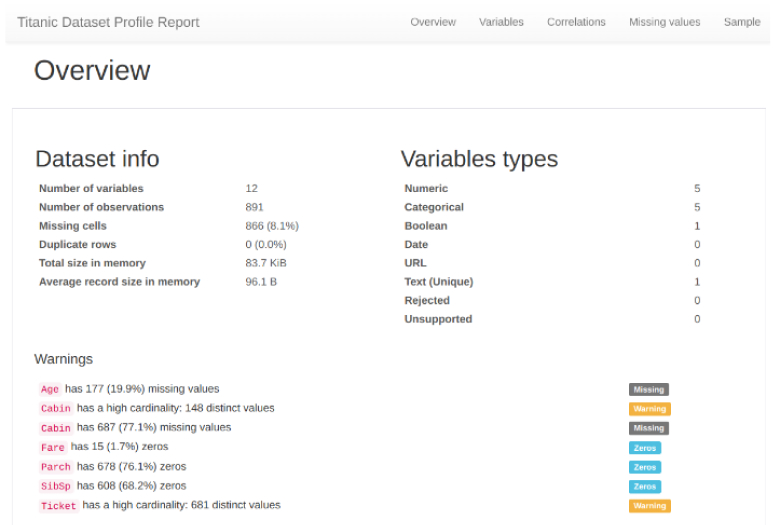
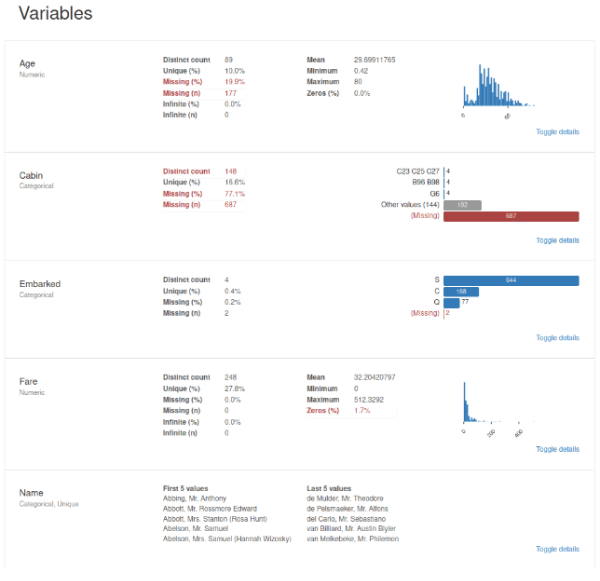
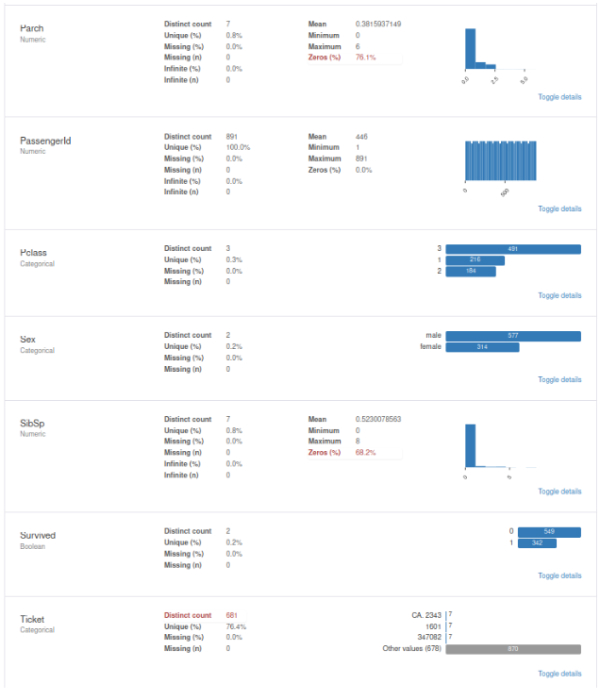
Variables:
Statistical analysis and plots for each variable.
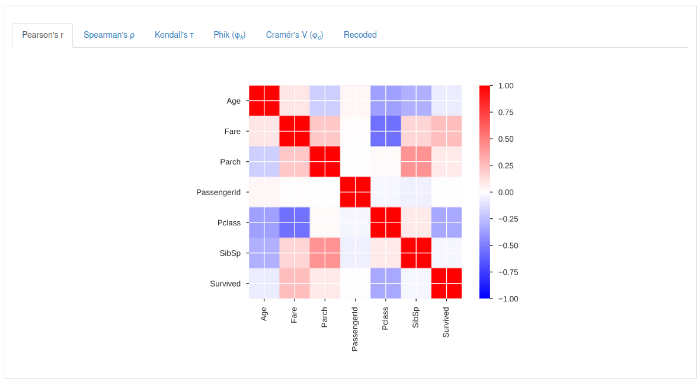
Correlations:
Computes correlation between variables using multiple like Pearson’s Correlation and Spearman’s Rank Correlation Coefficient.
Missing Values:
Plots charts for visualizing missing values. Here, 891 is the total number of data points. The bars with a count of less than 891 contain missing values.
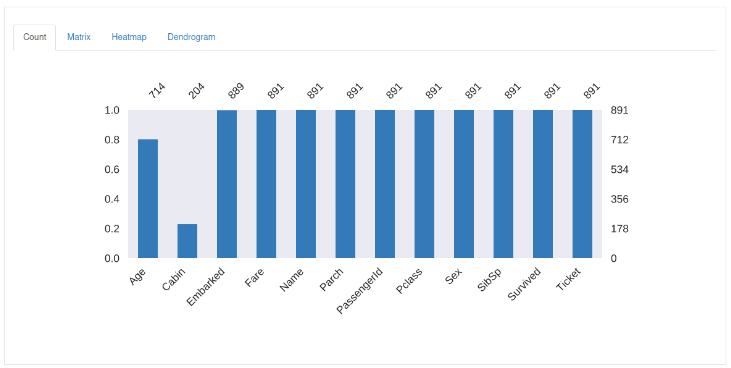
Handling Missing Values:
There are multiple techniques for handling missing values in datasets. The simple method is to remove observations with missing values. However, this can lead to lost information. Alternatively, missing values can be imputed based on patterns in the data.
Using mean imputation

Handling Outliers:
It is important to handle outliers carefully as they may be erroneous or simply unusual values. Model accuracy is affected by them. To reduce the impact of outliers, you can remove them or transform the data.
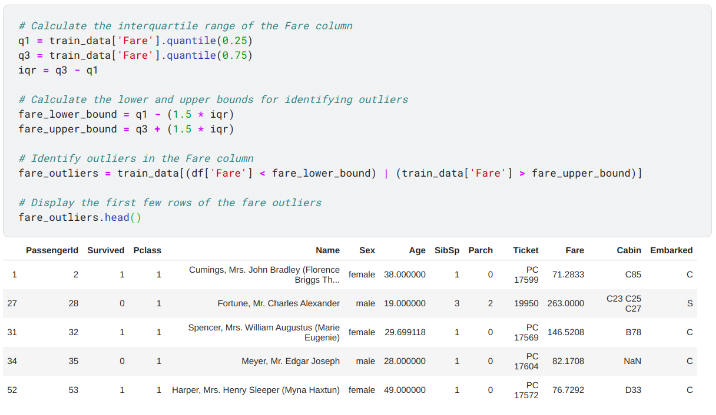
The interquartile range is a useful tool for removing outliers:
We first calculate the first quartile (q1), third quartile (q3), and interquartile range (IQR). Any value outside of this range is considered an outlier.
How To Use Coresets for Data Cleaning
Let’s take a stroll through the world of big data and explore a common problem faced by data scientists and machine learning experts.
Imagine you have been tasked to train a machine learning model using a dataset with millions of data points. The amount of data is overwhelming and would take considerable computational resources and time to train the model. Moreover, the data could be noisy and inconsistent and may contain errors that can make the model’s performance unreliable.
This is where coresets come into play! Coresets are subsets of the original data that are smaller but maintain key statistical properties. A coreset can significantly reduce computational complexity without losing data’s accuracy and reliability.
For example, considering the same dataset with one million data points, the brute force approach would be to use all one million data points, but as we already discussed, that would not be an optimal solution approach. Instead, you could create a coreset of, say, 10,000 data points that represent the key statistical properties of the original dataset. The smaller subset can then be used to train the model with similar results as if you had used the full dataset.
But how can coresets help with data cleaning?
Coresets can be used to efficiently identify and correct errors in the dataset.
Here’s how it works:
- First, a coreset is sampled from a small subset of the original dataset. – Sampling
- This coreset is then analysed for errors and inconsistencies. – Error Detection
- Any errors or inconsistencies are corrected in the coreset, and the corrections are propagated back to the original dataset. – Error correction and repropagation of errors
- This process is repeated multiple times with different coreset samples until no errors remain. – Re-sampling
Using coresets for data cleaning, the entire dataset need not be processed, saving computational resources and time. This approach is particularly useful when dealing with massive datasets common in machine learning, data science, and many other fields.
A Real-Life Example Where Data Cleaning Proved Invaluable
Did you know that a major data quality issue once caused Walmart to suffer significant revenue losses in the early 2000s? It was a nightmare for the retail giant, with inconsistent and inaccurate data across various systems and formats. That was until Walmart decided to take the bull by the horns and launch a data-cleaning initiative. The initiative consisted of consolidating data into a single data warehouse, standardizing data formats and codes, and validating data.
It took Walmart several years to complete this data-cleaning process, but the results were impressive. By improving the quality of its data, Walmart was able to adjust its pricing and inventory levels based on which products were selling well in which stores. The company saw a significant increase in revenue and profitability, all thanks to accurate data.
But Walmart is not the only industry that benefits from data cleaning. In healthcare, accurate patient information is essential for a reliable diagnosis and treatment plan. Financial data must be cleaned for financial models and investment decisions to eliminate errors and inconsistencies. In marketing, data cleaning is vital to ensure accurate customer information and eliminate irrelevant or invalid data. And with all the unnecessary noise and irrelevant data generated by social media platforms, data cleaning is crucial. In research, data cleaning is essential to ensure datasets are accurate and error-free.
Data accuracy, reliability, and consistency are critical for any application. So, the next time you encounter a data quality issue, remember Walmart’s story and the power of data cleaning to turn things around.
Conclusion
Data cleaning is crucial to processing and analysing data across industries. In order to make better decisions, data cleaning removes errors, duplicates, and inconsistencies. The success of Walmart’s data cleaning initiative, which increased revenue and profitability, shows how important data cleaning is.
Missing values are handled, duplicates are removed, outliers are handled, data structures are unified, errors are fixed when cross-set data is mixed, types are converted, and syntax errors are removed.
Automated data cleansing approaches such as coreset and active learning can reduce the effort and time required for data cleaning. As a result of coreset, the dataset can be reduced in size while preserving the same statistical properties, whereas active learning involves selecting the most informative data iteratively.
While data cleaning can be time-consuming, the benefits far outweigh the drawbacks. Healthcare, finance, marketing, and research benefit from data cleaning by ensuring data accuracy, reliability, and consistency.

