
Customer segmentation refers to a data-centric marketing approach that encompasses the separation of a customer clientele into clear-cut clusters according to shared attributes, behaviors, or inclinations. Through scrutinizing customer data like buying patterns, demographic details, and engagements, enterprises can extract meaningful observations and fine-tune their marketing endeavors to target precise customer segments.
This approach enables companies to create personalized and targeted marketing campaigns, deliver relevant products or services, enhance customer experiences, and ultimately drive customer loyalty and satisfaction. Customer segmentation empowers businesses to optimize resources, increase conversion rates, and stay competitive in today’s dynamic market landscape.
Various techniques are used for handling customer segmentation, and their usefulness depends on the nature of the data and the specific business goals. Today, we are going to explore one of them, i.e. KMeans.
Introduction to KMeans
KMeans is a widely used unsupervised machine learning algorithm for clustering data into distinct groups. It is an essential technique in data analysis, pattern recognition, and customer segmentation tasks. The primary objective of KMeans is to partition data points into K clusters, where each cluster’s data points are more similar to each other than to data points in other clusters.
How KMeans Works:
- Random Initialization: KMeans starts by randomly placing K cluster centroids in the data space.
- Assigning Data Points: Each data point is assigned to the nearest centroid, creating initial clusters.
- Updating Centroids: The centroids are recalculated based on the mean of the data points within each cluster.
- Reassigning Data Points: Data points are reassigned to the closest centroid based on the updated positions.
- Iterative Process: Steps 3 and 4 are repeated until the centroids stabilize and data points stop changing clusters.
Benefits of KMeans:
- Simplicity and Efficiency: KMeans is easy to understand and implement. It efficiently handles large datasets and can scale well.
- Interpretability: The resulting clusters are easy to interpret and can provide valuable insights into the data’s underlying structure.
- No Supervised Learning Required: KMeans is an unsupervised algorithm, meaning it doesn’t require labeled data, making it applicable to a wide range of problems.
- Scalability: KMeans performs well with large datasets and can handle high-dimensional data effectively.
- Versatility: KMeans is applicable in various domains, including customer segmentation, image segmentation, anomaly detection, and more.
- Baseline Comparison: It serves as a useful baseline for evaluating the performance of other more complex clustering algorithms.
- Fast Convergence: In many cases, KMeans converges quickly, making it efficient for quick data analysis and prototyping.
Introduction to “KMeans Coreset” from Dataheroes
The CoresetTreeServiceKMeans module in the DataHeroes library is a Python implementation of the Coreset Tree algorithm for K-Means clustering. The Coreset Tree algorithm is a technique that can be used to improve the speed of K-Means clustering by building a small subset of the original dataset, called a coreset, that is representative of the entire dataset. The K-Means algorithm is then applied to the coreset, and the results are used to cluster the original dataset.
The CoresetTreeServiceKMeans module provides a number of features that make it easy to use the Coreset Tree algorithm for K-Means clustering. These features include:
- A simple interface that makes it easy to build and train a Coreset Tree model.
- The ability to specify the number of clusters to be used.
- The ability to specify the number of samples to be included in the coreset.
- The ability to track the time it takes to build the coreset and train the model.
Data Exploration
We will be working on a customer segmentation problem including the following features:
- State_Code: Categorical, 8 Unique values.
- Ethnic_Group: Categorical, 8 Unique values.
- People_In_Household: Numeric, 8 Unique values.
- Home_Owner/Renter: Categorical, 2 Unique values.
- Occupation: Categorical, 26 Unique values.
- Vehicle: Categorical, 3 Unique values.
- Vehicle-dominant_lifestyle_indicator: Categorical, 7 Unique values.
- Education: Numeric, 4 Unique values.

Shape of data
Categorical to Numerical conversion
from sklearn.preprocessing import StandardScaler, LabelEncoder, OneHotEncoder label_encoder = LabelEncoder() columns_transform = ['State_Code','Occupation','Home_Owner/Renter','Ethnic_Group','Vehicle-dominant_lifestyle_indicator','Vehicle','People_In_Household','Education'] for col in columns_transform: reconstructed_df[col] =label_encoder.fit_transform(reconstructed_df[col])
Explanation
- Converting categorical values to numerical by the use of “Label Encoder”
- Label Encoder converts NaN values to 0 by default; we will be processing that further.
reconstructed_df = reconstructed_df.replace(0, np.NaN)
Explanation
- Replacing all 0s with np.nan as the NaN values were converted to 0 by default.
- Here, we are handling the biases of data that came into the picture after converting categorical to numerical values using a label encoder.
Imputation of NaN with Mode
columns_with_nan = reconstructed_df.columns[reconstructed_df.isnull().any()].tolist() for i in columns_with_nan: mode_value = reconstructed_df[i].mode().iloc[0] reconstructed_df[i] = reconstructed_df[i].fillna(mode_value)
Explanation
- Storing the feature names that have NaN values in them.
- Iterating over each feature, finding the mode of that feature, and imputing NaN with the mode of that particular feature.
Building Coreset
reconstructed_np = reconstructed_df.to_numpy()
X = reconstructed_np
from time import time
coreset_build_start_time = time()
service_obj = CoresetTreeServiceKMeans(
optimized_for='training',
n_instances=26_000_000,
coreset_size=20_000
)
service_obj.build(X)
coreset_build_time = time() - coreset_build_start_time
print(f"CoresetTreeServiceKMeans construction lasted {coreset_build_time:.2f} seconds")
Explanation
- The variable X stores the data as a numpy array.
- The CoresetTreeServiceKMeans class is a class that can be used to build a coreset for K-Means clustering. We create an instance of this class so that we can build the coreset.
- The build() method builds the coreset. We call this method on the service_obj object to build the coreset.

Building Coreset
elbow_method_num_clusters_interval = list(range(2,13))
Explanation
elbow_method_num_clusters_interval defines a list of integers from 2 to 12.
KMeans on Coreset
# Initialize a list of scores and fit times for the Coreset
elbow_method_scores_coreset = []
elbow_method_times_coreset = []
# Determine number of samples in the Coreset tree
coreset = service_obj.get_coreset()
_, coreset_x = coreset['data']
num_samples_in_coreset = len(coreset_x)
inertia_per_cluster_coreset = []
for k in elbow_method_num_clusters_interval:
coreset_kmeans_fit_start_time = time()
coreset_model = service_obj.fit(**{"n_clusters":k})
coreset_kmeans_fit_time = time() - coreset_kmeans_fit_start_time
cluster_inertia = 0
#Predicting clusters for full dataset
predictions_coreset = coreset_model.predict(X)
for i, cluster_center in enumerate(coreset_model.cluster_centers_):
cluster_points = X[predictions_coreset== i]
cluster_distances = np.linalg.norm(cluster_points - cluster_center, axis=1)
cluster_inertia+= np.sum(cluster_distances ** 2)
inertia_per_cluster_coreset.append(cluster_inertia)
elbow_method_times_coreset.append(coreset_kmeans_fit_time)
Explanation
- The code snippet first initializes two empty lists: elbow_method_scores_coreset and elbow_method_times_coreset. These lists will be used to store the inertia and fit times of the K-Means models that are fit on the coreset.
- Next, the code snippet determines the number of samples in the coreset tree. This is done by calling the get_coreset() method on the service_obj object. The get_coreset() method returns a dictionary that contains the coreset data. The number of samples in the coreset is the length of the coreset_x array.
- Finally, the code snippet iterates over the list of integers in elbow_method_num_clusters_interval. For each integer k in the list, the code snippet fits a K-Means model on the coreset with k clusters. The inertia of the model is then added to the inertia_per_cluster_coreset. The fit time of the model is then added to the elbow_method_times_coreset list.
dataset_coreset = pd.DataFrame({'Inertia': elbow_method_scores_coreset, 'Time Taken': elbow_method_times_coreset})
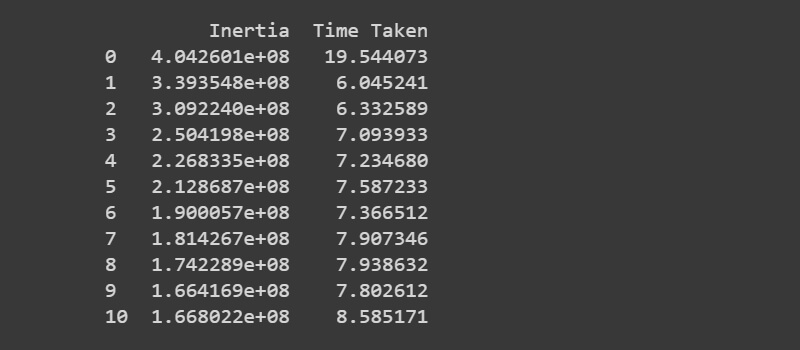
Results on Coreset
Explanation
- Creating the dataframe having elbow method score and time taken.
KMeans on full dataset
# Ignore convergence warnings for logistic regression
elbow_method_scores_full_dataset = []
elbow_method_times_full_dataset = []
num_samples_in_full_dataset = len(X)
for k in elbow_method_num_clusters_interval:
full_dataset_kmeans = KMeans(n_clusters=k)
full_dataset_kmeans_fit_start_time = time()
full_dataset_kmeans.fit(X)
full_dataset_kmeans_fit_time = time() - full_dataset_kmeans_fit_start_time
elbow_method_scores_full_dataset.append(full_dataset_kmeans.inertia_)
elbow_method_times_full_dataset.append(full_dataset_kmeans_fit_time)
Explanation
- The first line of code defines the variable elbow_method_scores_full_dataset and initializes it to an empty list.
- The second line of code defines the variable elbow_method_times_full_dataset and initializes it to an empty list.
- The third line of code defines the variable num_samples_in_full_dataset and initializes it to the length of the X array.
- The for loop iterates over the list of integers in elbow_method_num_clusters_interval.
- For each integer k in the loop, the code snippet first creates a K-Means model with k clusters.
- The code snippet then calls the fit() method on the K-Means model. The fit() method fits the model on the full dataset.
- The code snippet then calculates the inertia of the model and stores it in the elbow_method_scores_full_dataset list.
- The code snippet then calculates the fit time of the model and stores it in the elbow_method_times_full_dataset list.
dataset_full = pd.DataFrame({'Inertia': elbow_method_scores_full_dataset, 'Time Taken': elbow_method_times_full_dataset})
Explanation
- Creating the dataframe having elbow method score and time taken.
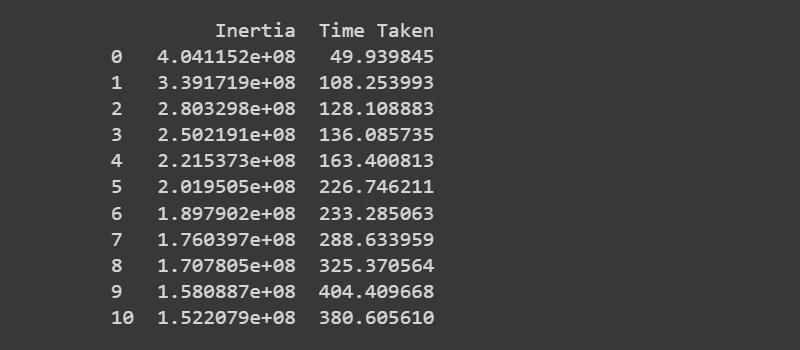
Results on Full Dataset
Conclusion
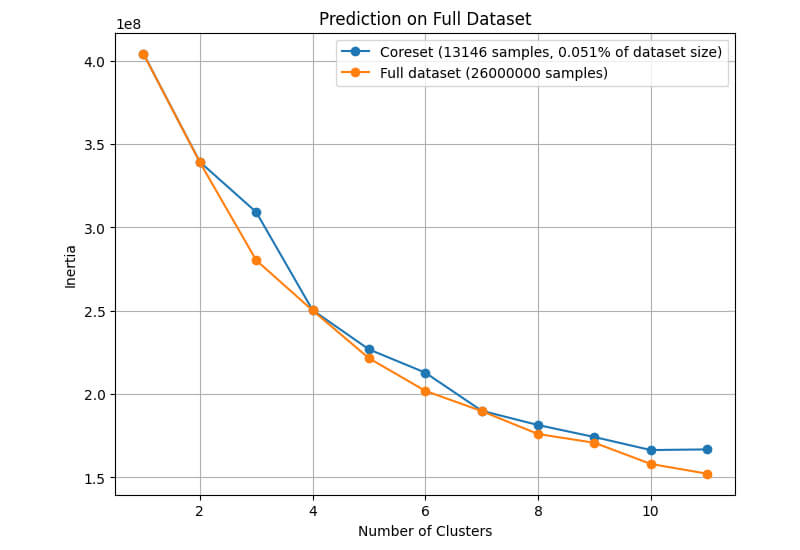
Coreset size – 20_000
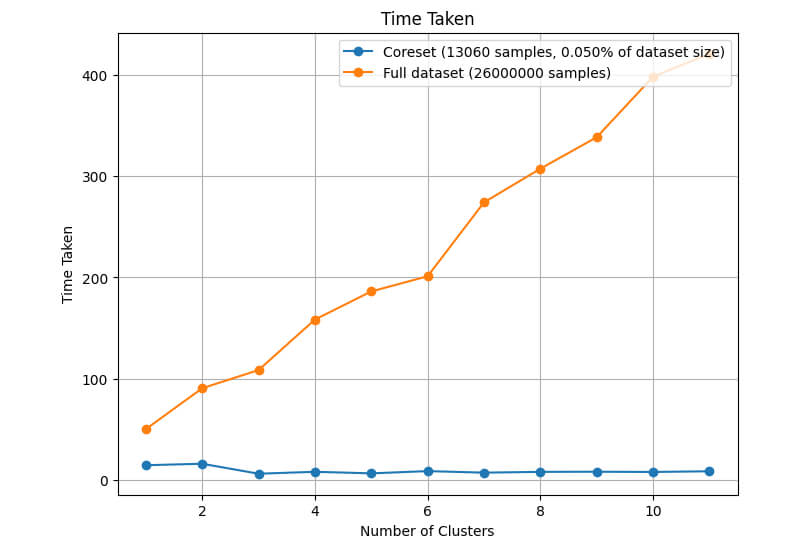
- CoresetTreeServiceKMeans from DataHeroes outperforms traditional KMeans in customer segmentation.
- It achieves better clustering scores and improved efficiency, especially for larger datasets.
- By utilizing the Coreset Tree algorithm, CoresetTreeServiceKMeans builds a representative subset of the data (coreset) for faster convergence.
- Businesses should prioritize using CoresetTreeServiceKMeans for customer segmentation to optimize resources and enhance marketing strategies effectively.
Results on various coreset size
![Coreset size - 300_000 [ 300 k ]](https://dataheroes.ai/wp-content/uploads/2023/10/coreset-size-300_000.jpg)
Coreset size – 300_000 [ 300 k ]
![Coresert size - 200_000 [ 200 k ]](https://dataheroes.ai/wp-content/uploads/2023/10/coresert-size-200k.jpg)
Coresert size – 200_000 [ 200 k ]
![Coreset size - 100_000 [ 100 k ]](https://dataheroes.ai/wp-content/uploads/2023/10/coreset-size-100_000.jpg)
Coreset size – 100_000 [ 100 k ]
![Coreset size - 50_000 [ 50 k ]](https://dataheroes.ai/wp-content/uploads/2023/10/coreset-size-50_000.jpg)
Coreset size – 50_000 [ 50 k ]

