
In recent years, Machine Learning Operations (MLOps) has emerged as a critical area of focus for organizations that rely on machine learning (ML) models to drive business outcomes. MLOps provides a framework for managing the entire ML lifecycle, from data preparation to model deployment, monitoring, and maintenance.
One critical aspect of MLOps is data drift detection, which ensures that the ML model’s performance remains accurate over time. Data drift, which is the slow and subtle changes in the input data, can significantly affect the accuracy of the ML model over time. Therefore, it is essential to monitor data drift and perform necessary actions to ensure the accuracy of the model’s performance.
Understanding the Importance of Data Drift Detection
Machine learning (ML) models are becoming increasingly popular in various industries due to their ability to automate decision-making processes, improve accuracy, and save time and resources. However, the performance of ML models heavily relies on the quality and relevance of the data they are trained on. In a real-world scenario, data distribution can change over time due to various reasons, such as changes in customer behavior, new business rules, and external factors like market fluctuations, leading to a phenomenon known as data drift.
Data drift occurs when the statistical properties of the input features or the target variable in the deployed environment differ from those in the training environment, leading to a decrease in the accuracy of the ML model. It is a common problem in machine learning, especially in applications where data is collected over a long period, such as predictive maintenance or fraud detection.
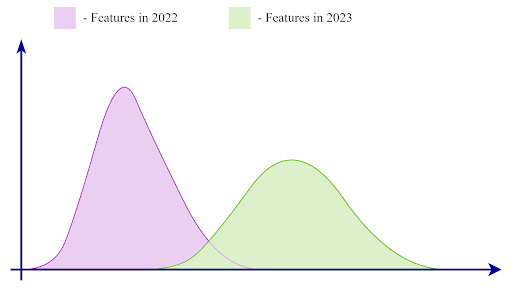
Illustration of Data Drift: The mean and variance of the feature curves may change over time.
Data drift can have significant consequences for businesses, including incorrect predictions, incorrect decision-making, and potential legal or financial liabilities. For instance, a self-driving car system that was trained on data collected from a specific geographic location may perform poorly when deployed in a different location due to changes in weather conditions, road infrastructure, and traffic patterns. Similarly, an insurance company’s fraud detection model may start making incorrect decisions if there is a sudden change in the distribution of fraudulent activities.
Therefore, it is essential to continuously monitor the performance of ML models and detect data drift early. This is where MLOps and data drift detection come into play. MLOps is a set of practices that enables the development, deployment, and management of ML models in production environments. Data drift detection is a crucial part of MLOps, ensuring that ML models continue to perform accurately over time.
By detecting data drift early, organizations can take appropriate action to maintain the accuracy of their ML models. This could involve retraining the model on new data, updating the features used to train the model, or adjusting the model’s parameters. By doing so, organizations can ensure that their ML models remain relevant and continue to provide accurate predictions, leading to better decision-making and improved business outcomes.
Types of Data Drift
The three main types of data drift that can occur are:
- Concept Drift: Concept drift occurs when the underlying relationship between the input features and the target variable changes over time. This means that the meaning of the features changes, leading to a change in the model’s output. For example, in the case of a credit scoring model, if the definition of a “good” or “bad” credit score changes over time, the model’s output will change, leading to a decrease in accuracy.
- Covariate Shift: Covariate shift occurs when the distribution of the input features changes over time, but the relationship between the features and the target variable remains the same. This means that the meaning of the features remains the same, but the frequency or range of the features changes. For example, if an ML model is trained to identify fraudulent credit card transactions based on a specific set of features, and the distribution of these features changes over time, the model’s accuracy will decrease.
- Prior Probability Shift: Prior probability shift occurs when the frequency of the target variable changes over time. This means that the likelihood of the target variable changes, leading to a change in the model’s output. For example, if an ML model is trained to predict the likelihood of a customer churning based on historical data, and the frequency of churners decreases over time, the model’s accuracy will decrease.
Detecting Data Drift
Detecting data drift is a critical component of MLOps. Several techniques can be used to detect data drift, including:
- Statistical Process Control Charts: Statistical Process Control (SPC) charts monitor and control a process over time. SPC charts can be used to monitor the distribution of input features and compare them to the training data distribution. If the distribution of the input features changes significantly, it may indicate the presence of data drift.
- Kernel Density Estimation: Kernel Density Estimation (KDE) is a non-parametric technique used to estimate the probability density function of a random variable. KDE can be used to estimate the distribution of the input features and compare them to the training data distribution. If the estimated distribution of the input features differs significantly from the training data distribution, it may indicate the presence of data drift.
- Distance-Based Methods: Distance-based methods measure the distance between the distribution of the input features and the training data distribution. These methods include Kullback-Leibler divergence, Jensen-Shannon divergence, and Bhattacharyya distance. If the distance between the distributions exceeds a certain threshold, it may indicate the presence of data drift.
- Model-Based Methods: Model-based methods involve retraining the ML model on a subset of the data and comparing its performance on the remaining data to its performance on the original training data. If the model’s performance decreases significantly, it may indicate the presence of data drift.
Machine Learning Models for Data Drift Detection
Machine learning models can also be used to detect data drift in addition to statistical methods. These models can learn patterns in the data and identify changes in those patterns that may indicate drift. Here are some popular machine learning models for data drift detection.
Support Vector Machines (SVM)
Support Vector Machines (SVM) is a popular machine learning model for data classification and regression tasks. SVMs can also be used for anomaly detection, including detecting data drift. SVMs can learn the boundaries between classes in the data and identify when new data points fall outside those boundaries, which may indicate drift.
from sklearn.svm import OneClassSVM # create a OneClassSVM object to detect anomalies in the data svm = OneClassSVM(kernel='rbf', nu=0.01) # fit the SVM on the training data svm.fit(X_train) # predict anomalies in the deployment data y_pred = svm.predict(X_deployment) # compute the percentage of anomalous data points drift_percent = (y_pred == -1).sum() / len(y_pred)
Random Forests
Random Forests are an ensemble learning method that combines multiple decision trees to improve predictive accuracy. Random Forests can also be used for anomaly detection, including detecting data drift. Random Forests can learn the patterns in the training data and identify when new data points deviate significantly from those patterns, which may indicate drift.
from sklearn.ensemble import IsolationForest # create an IsolationForest object to detect anomalies in the data rf = IsolationForest(n_estimators=100, contamination=0.01) # fit the Random Forest on the training data rf.fit(X_train) # predict anomalies in the deployment data y_pred = rf.predict(X_deployment) # compute the percentage of anomalous data points drift_percent = (y_pred == -1).sum() / len(y_pred)
Autoencoder Neural Networks
Autoencoder Neural Networks are a type of neural network that can learn a compressed representation of the input data. Autoencoder Neural Networks can also be used for anomaly detection, including detecting data drift. Autoencoder Neural Networks can learn the patterns in the training data and identify when new data points deviate significantly from those patterns, which may indicate drift.
import torch
import torch.nn as nn
import torch.optim as optim
# define the autoencoder neural network
class Autoencoder(nn.Module):
def __init__(self, input_dim, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, encoding_dim),
nn.ReLU())
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, input_dim),
nn.Sigmoid())
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# define the training and validation data
X_train = torch.randn(1000, 10) # example training data with 1000 samples and 10 features
X_val = torch.randn(100, 10) # example validation data with 100 samples and 10 features
# define the hyperparameters
input_dim = 10 # number of features in the data
encoding_dim = input_dim // 2 # encoding dimension of the autoencoder
learning_rate = 0.001
num_epochs = 10
batch_size = 32
# create an instance of the autoencoder neural network
autoencoder = Autoencoder(input_dim, encoding_dim)
# define the loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(autoencoder.parameters(), lr=learning_rate)
# train the autoencoder neural network
for epoch in range(num_epochs):
running_loss = 0.0
for i in range(0, X_train.shape[0], batch_size):
# get a batch of training data
inputs = X_train[i:i+batch_size, :]
# zero the parameter gradients
optimizer.zero_grad()
# forward pass
outputs = autoencoder(inputs)
# compute the loss
loss = criterion(outputs, inputs)
# backward pass and optimization
loss.backward()
optimizer.step()
running_loss += loss.item()
# print the average loss for the epoch
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/X_train.shape[0]}")
# encode the training and deployment data using the autoencoder
X_train_encoded = autoencoder.encoder(X_train).detach().numpy()
X_deployment_encoded = autoencoder.encoder(X_deployment).detach().numpy()
# compute the reconstruction error between the training and deployment data
mse = ((X_train_encoded - X_deployment_encoded) ** 2).mean(axis=1)
# compute the percentage of anomalous data points
drift_percent = (mse > threshold).sum() / len(mse)
Best Practices for MLOps and Data Drift Detection
To ensure the accuracy of ML models, following some set principles for MLOps and data drift detection is essential. The following are some of the best practices for MLOps and data drift detection.
Start with a well-defined problem statement
Clearly define the problem you are trying to solve with machine learning, including the specific business use case, the expected inputs and outputs, and the success criteria. This will help you focus on the most important aspects of your model’s performance and the data you need to monitor for drift.
Establish a baseline
Before deploying your model, establish a baseline performance metric using a holdout dataset or a previously collected dataset that is representative of your production environment. This will allow you to compare future performance to the baseline and detect drift.
Collect high-quality data
Collecting high-quality data is essential for ensuring the accuracy of the ML model. It is essential to collect data from reliable sources and ensure that it is labeled and cleaned appropriately. MLOps provides a data collection and management framework, including data cleaning, preprocessing, and labeling.
To learn more about the best techniques for better data cleaning, check out this article: 5 Data Cleaning Techniques for Better ML Models
Monitor input data regularly
Monitoring input data regularly is essential for detecting data drift. This involves regularly comparing the input data to the training data to detect any changes. This could include monitoring statistical properties of the data, such as mean and variance, or using techniques like kernel density estimation to visualize the data distribution. If data drift is detected, appropriate actions must be taken to ensure that the model continues to perform accurately.
import pandas as pd
# load the data
data = pd.read_csv("data.csv")
# calculate the mean of a feature
feature_mean = data["feature"].mean()
# check if the mean has changed from the baseline
if abs(feature_mean - baseline_mean) > threshold:
print("Data drift detected!")
Monitor model performance
Monitoring model performance is essential for ensuring that the model continues to perform optimally. It involves regularly monitoring and comparing the model’s output to the expected output. This could include monitoring the distribution of model outputs or using techniques like Shapley values to identify the most important features for the model’s predictions. If the model’s performance is not up to par, appropriate actions must be taken to update and optimize the model.
import matplotlib.pyplot as plt
# generate example model outputs
outputs = model.predict(X)
# plot the histogram of the model outputs
plt.hist(outputs, bins=20)
# compare to the baseline distribution
baseline_outputs = model.predict(baseline_X)
plt.hist(baseline_outputs, bins=20, alpha=0.5)
# check if the distributions are significantly different
if ks_test(outputs, baseline_outputs) > threshold:
print("Data drift detected!")
Retrain the model
If data drift is detected, retrain the model using the latest data to ensure that it continues to perform accurately. This could involve using techniques like transfer learning to update the model without starting from scratch or active learning to selectively label new data that will most likely improve the model’s performance.
Use Coresets
Re-training a model with the entire dataset is often computationally extremely expensive and time-consuming, especially in this information era where a large amount of training data is readily available. As a result, retraining the model is avoided for as long as possible, therefore enabling data drift to occur.
A Coreset is (usually) a small, weighted subset of the original input set of items, such that fitting an ML model on the Coreset will yield the same parameters as fitting it on the original big data. The DataHeroes Coreset tree structure allows you to add new data, update the Coreset on the go, and re-train your model on the Coreset in near real-time, thus making it easy to avoid data drift.
Coresets can lower your model update time to minutes or hours and lower the costs significantly, thus making it practical to update your model as frequently as needed and avoid data drift altogether.
Learn more about the best practices for ML model training for optimal model performance.
For other reasons to use Coresets, check out this video.
How to implement Coresets
In Python, the DataHeroes library can be easily installed using ‘pip install dataheroes’. As an example, to build a Coreset for Logistic Regression, of a dataset with 406K samples and 7 classes stored in a CSV file using the DataHeroes library, we only need a few lines of code:
from dataheroes import CoresetTreeServiceLG
service_obj = CoresetTreeServiceLG(data_params=data_params,
optimized_for='training',
n_classes=7,
n_instances=406_000
)
service_obj.build_from_file(train_file_path)
Now to get the Coreset from your dataset use the following code.
# Get the top level coreset (~2K samples with weights, in this case) coreset = service_obj.get_coreset() indices, X, y = coreset['data'] w = coreset['w']
Finally, to use this coreset to train a Logistic Regression model, you can simply do the following.
coreset_model = LogisticRegression().fit(X, y, sample_weight=w)
To follow a more in-depth step-by-step Python tutorial for building your own Coreset for model training, follow this easy GitHub documentation.
Now, suppose you need to change the labels of some samples after getting some more analytics post-production. You can obtain the “important” samples in the coreset, i.e., the samples that impact the model the most (in the example below, the 50 most important samples from the ‘non_defect’ class), and then update the labels for them (to the ‘defect’ class, in the example below) using the following code.
indices, importance = service_obj.get_important_samples(class_size={‘non_defect’: 50})
service_obj.update_targets(indices, y=[‘defect’] * len(indices))
You may even want to remove some samples entirely from the data. You can do that using the following code and then check the performance (AUROC) of the updated coreset.
# Removing the samples indices stored in the array `idxes_to_delete` from the Coreset service_obj.remove_samples(indices=idxes_to_delete)
Follow these detailed articles to find and fix labels in image classification, object detection, semantic segmentation, and NLP datasets.
Implement version control
Implementing version control is essential for managing the ML model’s code and documentation. It involves keeping track of the changes made to the model’s code and documentation, ensuring that the changes are documented and stored appropriately. Using version control tools like Git, you can track changes to your machine learning models and datasets over time.
Conclusion
MLOps and Data Drift Detection are essential for ensuring the accuracy of ML models. It can significantly affect the accuracy of the model’s performance over time. By detecting data drift early, organizations can take appropriate action to maintain the accuracy of their ML models and avoid potential consequences such as incorrect decision-making or financial liabilities. Therefore, it is essential to monitor data drift and perform necessary actions to ensure the accuracy of the model’s performance.
MLOps provides a framework for managing the entire ML lifecycle, including data drift detection. Following the best practices for MLOps and data drift detection mentioned in the article can help ensure that the ML model continues to perform optimally throughout its lifecycle.

