
The Goal of the Article
We will use the DataHeroes Coreset library to find labeling mistakes in the Ag News NLP dataset. First, we will select a class with potentially dirty labels to find and clean. Then, using the DataHeroes library, we will find instances with a high probability of being mislabeled by building a Coreset and using the Coreset’s Importance property.
We pre-processed the text into embedding using a pre-trained BERT model. By doing this, we can successfully build a logistic regression coreset on top of the resulting embeddings.
Overview of the Main Steps Within the Article
- Process AG News (dataset details) data to create text embeddings.
- Load AG News data (raw text and embeddings).
- Clean the labels using the DataHeroes Coreset Package.
- Visualize results.
Before we get started, please make sure to import and correctly set up the DataHeroes library. If you are new to this, you can find out more here.
Process AG News data
In this blog post, we are concerned with better understanding and cleaning a news dataset in the context of a classification problem. To achieve this, we need to represent the text data in a numerical format suitable for this task. A popular approach is to convert the text into embeddings.
Word embeddings are dense vector representations that capture the semantic meaning of the words and their relationships with other words in the vocabulary.
One popular approach to generate word embeddings is to use a pre-trained language model, for example, Word2Vec or BERT. In this tutorial, we are using HuggingFace’s pre-trained BERT model to generate 768 components embedding.
import os
import numpy as np
from datasets import load_dataset, concatenate_datasets
from torch.utils.data import DataLoader
from transformers import pipeline
# Load dataset
dataset = load_dataset(*("ag_news",))
# Pick the splits
try:
train_dataset = concatenate_datasets([dataset["train"], dataset["validation"]])
except KeyError:
train_dataset = dataset["train"]
train_dataset = train_dataset.shuffle(seed=42).select(
range(min(len(train_dataset), 100000))
)
To download the BERT embeddings, we initialize a HuggingFace feature extraction task to return a tensor using model=”bert-base-cased”, a max_length=512, and framework=”pt”. Moreover, we dropped the last classification layer of the model to output an embedding instead of the class distribution.
# Create the extractor pipeline
feature_extractor = pipeline(
task="feature-extraction",
model="bert-base-cased",
framework="pt",
return_tensor=True,
device='gpu',
max_length=512,
truncation=True,
padding="max_length"
)
Loading the training dataset and initializing the feature extraction pipeline, we proceed with loading the data, extracting features, and saving the results for later use.
# Export the data
def export(dataset, suffix: str):
dataloader = DataLoader(dataset, batch_size=16)
aggregated_raw_input = []
aggregated_features = []
for batch in dataloader:
batch = batch["text"]
aggregated_raw_input.extend(batch)
results = feature_extractor(batch)
for result in results:
result = np.array(result)
features = np.max(result, axis=1)
aggregated_features.append(features)
aggregated_raw_input = np.array(aggregated_raw_input)
aggregated_features = np.vstack(aggregated_features)
aggregated_labels = np.array(dataset["label"])
raw_path = os.path.join(DATA_DIR, f"raw_{suffix}")
features_path = os.path.join(DATA_DIR, f"x_{suffix}")
labels_path = os.path.join(DATA_DIR, f"y_{suffix}")
np.save(raw_path, aggregated_raw_input)
np.save(features_path, aggregated_features)
np.save(labels_path, aggregated_labels)
return aggregated_features, aggregated_labels
export(train_dataset, suffix="train")
Note that these steps are part of a different script, which takes longer to run. Also, before you run the script, please install all the required dependencies and initialize the feature extraction pipeline using the correct device (GPU or CPU), depending on what you have available on your machine.
Load the AG News data
The data you need for this notebook is placed here. We will download the contents of a folder called AG_News and place the data at data/ag_news. The download may take a few minutes if the folder size exceeds 1GB.
The folder contains three files.
– raw_train.npy: Raw text data
– x_train.npy: Text embeddings of every sample.
– y_train.npy: Labels for every sample. There are four classes: World, Business, Sports, and Sci/Tech. Moreover, the data is balanced, with approximately the same number of samples in each class.
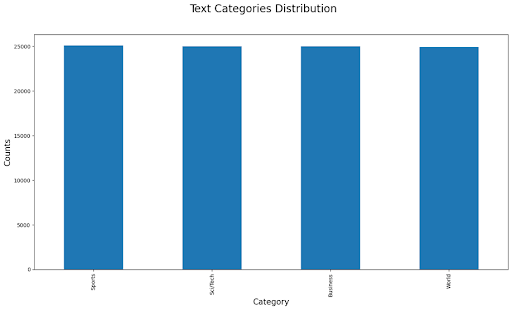
Figure 1. Class distributions. Note that the original AG News data contains an approximately equal number of samples for each news type.
Before cleaning, we wanted to visualize a couple of data samples. Below are a few news examples classified as belonging to the class “World” in the raw dataset.
Text: Car bomb explodes in Mosul, wounding 5 MOSUL, Iraq — A car bomb exploded Friday near an American armored vehicle in the northern Iraq city of Mosul, wounding five US soldiers, the military said.
Label Name: World
Text: Canada considers fate of suspected NKorean refugees in China <b>…</b> Canada is facing a diplomatic headache after a group of suspected North Koreans broke into the Canadian Embassy in the Chinese capital, Beijing, on Wednesday.
Label Name: World
Clean the labels Using the DataHeroes Coreset Package
We will use the Coreset service Importance property to find samples that may be incorrectly labeled. The process works by building a Coreset using the CoresetTreeServiceLG service and then reviewing instances that receive a high Importance score during the Coreset calculation. High importance scores indicate a greater likelihood of mislabelling, out-of-distribution, or other anomalies. Thus, we increase our chances of detecting dirty labels by selecting the top N samples with the highest importance scores.
We provide below the function definition that identifies the top N samples with the highest importance scores, given a set of features X and labels y for a particular class of interest.
def get_top_important_samples(service: CoresetTreeServiceLG,
of_interest_class_id: int = 0,
top_n_samples: int = 500) -> Tuple[np.array, np.array]:
"""
Extract the top N important samples for a given class from a CoresetTreeServiceLG object.
The function returns a tuple containing the indices and the importance
values of these samples.
:param service: A CoresetTreeServiceLG object representing the logistic regression model
:param of_interest_class_id: An integer representing the class ID of interest. The default value is 0.
:param top_n_samples: An integer representing the number of top important samples to retrieve. The default value is 500.
:return:
A tuple containing the indices and the importance values of the top N important samples.
"""
result = service.get_important_samples(
class_size={of_interest_class_id: "all"}
)
important_sample_indices, important_sample_values = result["idx"][:top_n_samples], result["importance"][:top_n_samples]
return important_sample_indices, important_sample_values
Before proceeding with data cleaning, we require an additional component to complete our puzzle. This component involves a method for updating the Coreset with the correct labels. Using this approach, we can construct the entire Coreset only once, at the beginning of the process, and subsequently, update the Coreset after each cleaning iteration. This methodology yields a significant computational advantage, as the computations involved in building the Coreset are only executed once.
Furthermore, our dataset has only two cleaning actions: altering a label or removing a sample. Given the nature of our dataset and these specific actions, the approach of updating the Coreset with the cleaned data is well-suited for our task.
def update_service(service: CoresetTreeServiceLG, cleaned_targets: dict) -> CoresetTreeServiceLG:
"""
Update an existing CoresetTreeServiceLG object by changing target labels or removing data samples
based on the changes specified in the cleaned_targets dictionary.
:param service: A CoresetTreeServiceLG object representing the logistic regression model
:param cleaned_targets: A dictionary containing the changes to be made. The dictionary has two keys:
'change_index': A dictionary where the keys are the class IDs and the values are lists of sample indices to be changed.
If a sample index appears in more than one list, its target label will be changed to the last value it appears in
the dictionary.
'drop': A list of sample indices to be removed from the coreset.
:return:
The updated CoresetService object.
"""
# Change target values
for target_class_id, sample_indices_to_change in cleaned_targets['change_index'].items():
if len(sample_indices_to_change):
target_class_ids = [target_class_id] * len(sample_indices_to_change)
service.update_targets(sample_indices_to_change, target_class_ids)
# Drop samples
if len(cleaned_targets['drop']):
service.remove_samples(cleaned_targets['drop'])
print('..Finished updating service...')
return service
With the two methods at our disposal, we can commence the data cleaning process. Initially, we must select a class of interest. In this tutorial, we employed visual inspection of the data to identify the class of interest. Specifically, we determined that the “World” class requires cleaning. For more intricate scenarios, a more robust approach may be necessary. For example, selecting a class using the confusion matrix (an example of which can be found here) could be utilized.
Once the class of interest has been established, we may begin the five-step cleaning process.
- Build a Coreset
- Extract top N samples with the highest importance that we haven’t seen so far
- Manually correct the samples (either change a label or mark a sample for removal)
- Update the Coreset with the corrected samples
- Compute the balanced accuracy based on the corrected labels using a K-fold-cross-validation
- Repeat steps 2-5 until the balanced accuracy score plateaus, or there are just a few incorrect labels discovered among the top importance samples
To facilitate the cleaning task, we created a straightforward interface that allows us to modify labels in real time. While the cleaning process is case-dependent and can be tedious, we will only highlight the primary components to maintain conciseness in this article.
The cleaning process involves two potential actions:
- Validation of news samples as belonging to the “World” class or assigning them to a different category (“Sports”, “Business”, “Sci/Tech”). This process may be subjective in certain instances, as there are cases where a news item may belong to multiple categories or does not align with the labeler’s definition of a “World” news item.
- Deletion of samples. This action may not always be clear-cut and can involve ambiguous news items or samples belonging to an invalid category. Before commencing the cleaning process, it is critical to establish a clear definition of what constitutes a valid “World” news item. If multiple labelers are involved in cleaning the data, they should employ identical definitions to avoid introducing biases.
It is essential to note that before commencing the cleaning process, several samples should be examined to define clear guidelines about valid and harmful labels. Failure to establish these guidelines may lead to more harm than good during the cleaning process. The Coreset approach can be particularly helpful in this regard, allowing for quick examination of the most significant samples that define the statistical properties of the dataset.
We initialize a set of parameters to keep track of the performance improvements obtained during the cleaning process and the number of samples we are changing with every iteration.
# Dictionary used for storing the results (balanced accuracy, number of viewed samples, number of cleaned samples)
# after every cleaning iteration.
results = {
'viewed_samples': [0],
'cleaned_samples': [0],
'balanced_accuracy': defaultdict(list)
}
# Index for the last current iteration
cleaning_iteration = 0
# Evaluate model on original data
balanced_accuracy = cross_val(X, y, scoring='balanced_accuracy')
results['balanced_accuracy'] = aggregate_scores(balanced_accuracy, results['balanced_accuracy'])
print(f"Raw data balanced accuracy: {balanced_accuracy[of_interest_class_id]:.2f}")
Let’s see an example of an iteration
Steps 1 & 2: We extract the top N important samples from the Coreset. In our example, we used 500 samples with the highest importance. Below you can see some examples of the instances with the highest Importance for the first iteration, together with their Importance value. Note that this metric is relative and is used for ranking samples.
***** Top Importance *****
Text: Tennis: Sharapova wins finale Maria Sharapova beats Serena Williams 4-6 6-2 6-4 in the Tour Championships final.
Label Name: World
Importance Value: 30986.58
Sample Index: 89787
——————————————————————–
Text: Massu Defeats Kucera at CA Trophy Olympic champion Nicolas Massu defeated Karol Kucera 6-4, 6-7 (5), 6-4 at the CA Trophy tournament on Tuesday.
Label Name: World
Importance Value: 29009.60
Sample Index: 16061
——————————————————————–
Text: Incredibles tops Nemo film record Animated film The Incredibles beats Disney/Pixar’s previous US box office record for Finding Nemo.
Label Name: World
Importance Value: 27853.08
Sample Index: 61077
Furthermore, we can also visualize the histogram of the importance values attached to each sample.
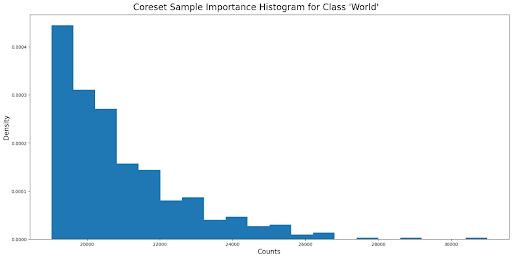
Figure 2. Importance values for 500 samples. Note how there are some instances with very high importance compared to the rest of the items in the samples. These values correspond to the samples that are incorrectly labeled.
Step 3: We manually reviewed each sample and corrected them based on the following actions: choose the label between “Word”, “Sports”, “Business”, or “Sci/Tech”, or delete the sample if the news item is ambiguous, contains unintelligible text, or is written in another language than English.
Steps 4 & 5: Update the Coreset with the corrected or removed samples from Step 3. Next, compute the balanced accuracy score using K-fold cross-validation. Finally, aggregate the results for subsequent visualization.
We stop the process when the balanced accuracy plateaus.
Visualize the results
Balanced accuracy score across iterations
The first result we want to check is the balanced accuracy. Figure 3 shows the results of four cleaning iterations. As can be seen from the figure, the balanced accuracy improved by ~1% just by cleaning approximately 600 samples.
Note that the AG News is a well-known dataset that is relatively clean. However, it is important to note that even in such a scenario, we still managed to improve the balanced accuracy score by fixing some of the labels. Therefore, this method shows great potential for real-world systems, where the data is dirtier and much more difficult to debug.
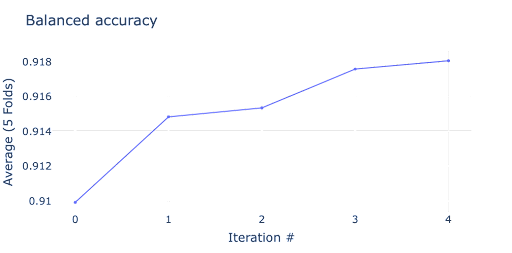
Figure 3. Balanced accuracy evolution after four cleaning iterations. Note that the accuracy improved from 0.91 to 0.918 after just four iterations.
Fixed Samples Across Iterations
Using the method described in this article, we speculate that this strategy also significantly reduces the time spent cleaning and debugging the data. As shown in Figure 4, we achieved a balanced accuracy improvement by cleaning ~30% of all the data samples we looked at.
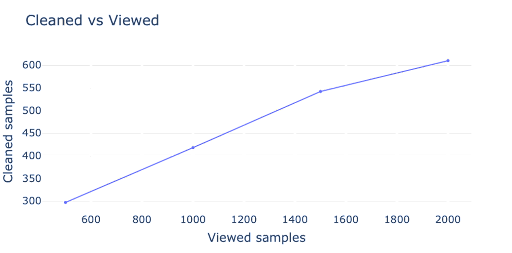
Figure 4. Number of cleaned vs. viewed samples. Note how the number of cleaned samples reduces after every iteration.
Conclusion
In conclusion, using the DataHeroes Coresets library, we used an innovative way to find instances with potentially faulty labels. Thus, speeding up the process of debugging and understanding your dataset.
After deciding on a class of interest, we used the Coresets logistic regression engine to calculate the Importance values of our class of interest.
Next, we reviewed the high Importance samples of the class. We have found wrongly annotated samples within the top percentile of our samples.
Finally, we conducted four cleaning iterations, seeing 500 samples during each iteration chosen based on the top importance values computed by the Coreset. At the end of the cleaning cycle, we observed that the balanced accuracy increased by approximately 1% after cleaning 600 samples out of 2000 viewed samples.

