
The Goal of the Article
Our approach involves using the DataHeroes Coreset service to clean the class labels in the COCO dataset. By adhering to best practices, we will select a particular class that is susceptible to having faulty labels and employ the Coreset service to introduce an innovative sampling method for identifying instances with a high likelihood of being mislabeled. This method will enable a more structured approach to the data-cleaning process, in contrast to the random sampling approach, which is often unreliable.
The purpose of this tutorial is to demonstrate the proper utilization of the Coreset service to efficiently and effectively cleanse your dataset. Specifically, we aim to clean or validate the class for every segmentation mask in the COCO dataset beyond what is achievable with random sampling.
Let’s start 🔥
Overview of the Main Steps Within the Article
- Install requirements and import dependencies
- Load COCO Features
- Pick a Class to Clean
- Clean the Labels Using the DataHeroes Coreset Package
- Visualize the Final Result
In Python, you can simply import the DataHeroes logistic regression service using the following command:
#Import the logistic regression coresets service, which we will use to clean the dataset. from dataheroes import CoresetTreeServiceLG
Note: Remember to set up the license key before using it. Check the website for instructions.
Load COCO Features
How We Computed the Features👇
The features we plan to import have already been precomputed by a separate script using the COCO dataset and the following procedures.
- We used a pre-trained ResNet50 classifier on COCO, excluding the last classification layer, to generate an embedding rather than a class distribution.
- We isolated each instance in the COCO dataset with the segmentation mask applied and treated it as an independent sample (with `iscrowd=False`). Consequently, we now have samples containing only one object/class instance.
- We passed all the images with the mask applied through the ResNet50 model, which produced a 2048 embedding. We can use the logistic regression service from the Coresets to compute the importance of each sample for the final classification. It is essential to note that a different Coreset service is available for every distinct model; the service we are using utilizes the logistic regression model as its foundation.
- We applied PCA on the embeddings to reduce the dimensions to 256. We will utilize the reduced dimension samples solely to train an LG model to facilitate the identification of the class we wish to clean.
NOTE: We moved these steps to a different script, which takes a few hours to run. Also, you need a GPU and extra dependencies to run it properly. Thus, we wanted to keep this article as light as possible.
We will use the load() function to import the precomputed representations of COCO bounding boxes, which include both 2048 and 256 dimensions:
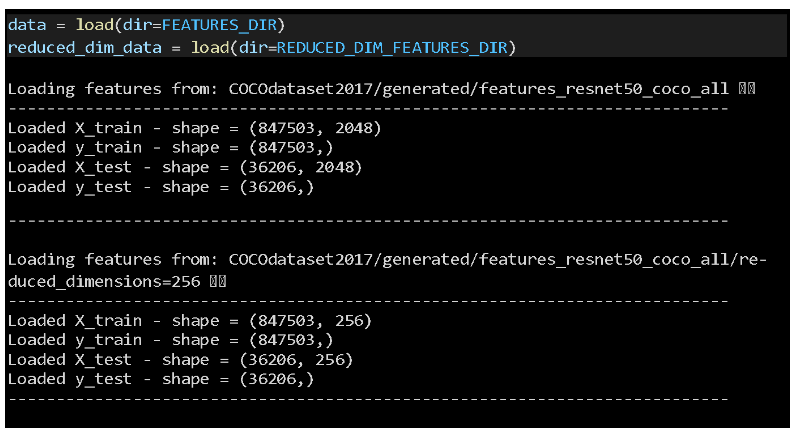
Load COCO Metadata
To load and analyze the COCO training annotations file, we use the Python package called pycocotools:
coco_train = COCO (DATA_DIR / "annotations" / "instances_train2017.json")
We have defined a group of rendering functions that allow us to display and store each segmentation mask from the COCO dataset in an appealing way. For the sake of simplicity, we have incorporated this code solely in the notebook.
To illustrate, we present a random segmentation mask. We have exported it in three different formats: the unprocessed image, the attention mask that highlights the labeled object (since identifying the segmentation mask can be difficult in certain scenarios), and the segmentation mask displayed on top of the original image.

Pick a Class To Clean
Our objective is to compute the Importance of a single class of interest. We will use logistic regression on our training dataset and choose the poorest-performing category as the class of interest.
In order to speed up the training time, the logistic regression model will only be trained on 256 embeddings that were reduced from 2048 through PCA.
clf = LogisticRegression (class_weight="balanced", max_iter=500) clf = clf.fit(reduced_dim_data["X_train"], reduced_dim_data["y_train"])
Pick the Class Based On the Confusion Matrix
We will use the confusion matrix to identify the class responsible for generating the highest number of false positives. Here’s an example to help you understand this process better.
We generated a normalized confusion matrix (comprising values between 0 and 1) for five classes, namely A, B, C, D, and E. After analyzing the matrix, we discovered that the highest value occurred between the true class A and the predicted class C (excluding those on the main diagonal). This indicates that within our testing data, class A was frequently confused with class C (samples of class A were classified as class C). As a result, we will consider class C as our class of interest because the high level of confusion between classes A and C might have resulted in labeling inconsistencies.
In our blog post about object detection dataset cleaning, we discovered that the `orange` class was most often confused with the other classes; in other words, that could indicate the fact that the `orange` class may be prone to labeling inconsistencies. For that reason, we may want to do some investigations and see if there are any issues with the labels which can cause our model to perform poorly in that specific class.
After conducting some analysis, we discovered that the “orange” class, which is our class of interest, has a total of 6300 samples (or segmentation masks).
NOTE: To speed up the training, we kept only samples from our class of interest, namely “orange.” Ultimately, we will use the Coreset service to sample only “orange” instances. Thus, this decision won’t affect the cleaning process but will speed up experimentation. After keeping only the segmentation masks from the `orange` class, the training data size was reduced from 847,970 to 6300 samples.
Clean the Labels Using the DataHeroes Coreset Package
We will use the Coreset service as a unique sampling technique to review samples with incorrect labels. So how does it work exactly?
With the help of `CoresetServiceLG,` we will calculate an Importance score for each sample in our dataset. Samples with a high Importance score are more likely to be mislabeled, out of distribution, or have other anomalies (such as occlusion, blurring, or strange shapes). Therefore, we have a high chance of uncovering dirty labels by selecting the top N samples with the highest importance. Random sampling is another common approach to data cleaning. However, when dealing with large datasets (as is often the case in real-world scenarios), randomly selecting samples and hoping to find errors becomes impractical. With the Coresets, we can ensure that we only review samples with a high potential for being mislabeled.
Below, you will find the function definition that identifies the top N samples with the highest importance values, using a set of features X and labels y for a specified class of interest.
def compute_importance(
X: np.ndarray,
y: np.ndarray,
of_interest_class_id: int,
export_n: int,
service: Optional[CoresetTreeServiceLG] = None
) -> dict:
"""Function that uses the coreset logistic regression service to find top N important samples from the given data.
Args:
X (np.ndarray): input features
y (np.ndarray): input labels
of_interest_class_id (int): the class to look at and export from
iteration (int): current cleaning iteration
export_n (int): the top number of samples to export
service (CoresetTreeServiceLG): if the Coreset service is given as a parameter, it will be directly used to compute the importance. Otherwise, it will be built before calculating the importance.
Returns:
dict: dictionary containing the results from the coreset computation: top importance values, indices, and an aggregated array of viewed indices
"""
if service is None:
start_service_time = time.time()
service = CoresetTreeServiceLG(optimized_for='cleaning')
service.build(x, y)
end_service_time = time.time()
print("Coreset computed in {end_service_time - start_service_time:.2f} seconds.")
result = service.get_important_samples(
class_size={of_interest_coco_class_id: export_n}
)
important_sample_indices, important_sample_values = result["idx"], result["importance"]
return {
"service": service,
"important_sample_indices": important_sample_indices,
"important_sample_values": important_sample_indices,
}
Our next step involves creating a final component that will enable us to update the Coreset service with the cleaned data. By using this approach, we will construct the entire Coreset service only once, initially. After every cleaning iteration, we will simply update the Coreset with the newly cleaned data and compute the AUC score based on the newly cleaned labels. This approach encompasses two potential cleaning actions: changing the label or removing the sample.
def clean(
service: CoresetTreeServiceLG,
X_train: np.ndarray,
y_train_slim: np.ndarray,
sample_weights: np.ndarray,
metadata_train: pd.DataFrame,
iteration: int,
) -> dict:
"""Function that takes the previous input and labels and cleans them based on cleaning actions from the given iteration. Also, it computes the AUC score on the newly cleaned labels.
Args:
service (CoresetTreeServiceLG): trained coreset LG service X_train (np.ndarray): input features y_train_slim (np.ndarray): dirty input labels sample_weights (np.ndarray): dirty sample weights metadata_train (pd.DataFrame): COCO metadata from the train split iteration (int): iteration from which to load the cleaning actions
Returns:
dict: a dictionary with the cleaned labels and weights plus the AUC scores
"""
# Load corrections and adapt y_train_slim and sample_weights.
corrections = read_iteration(iteration)
corrected_data = correct_labels(
y_train_slim=y_train_slim,
sample_weights=sample_weights,
corrections = corrections,
metadata_train=metadata_train,
iteration=iteration
)
# Update the service object with the corrections.
update_coreset_service(
service=service,
X=X_train,
y=corrected_data["y_train_fixed"],
sample_weights=corrected_data["sample_weights_fixed"],
corrections-corrections,
)
#Compute scores.
per_class_scores = eval_lg_cross_validation(
X=X_train,
y=corrected_data["y_train_fixed"],
sample_weights-corrected_data["sample_weights_fixed"]
)
return {**corrected_data, "scores": per_class_scores, "service": service}
Finally, Let’s Start Cleaning
The cleaning process is split into multiple iterations. For every iteration, we will do the following:
- Determine the importance of each sample by using the Coreset service.
- Select the top N samples with the highest importance score we have not yet reviewed (in our case, N = 60).
- Manually review and correct the selected samples.
- Load the corrected samples and update the corresponding labels.
- Calculate the AUC metric based on the updated labels using K-fold cross-validation.
- Repeat steps 1 through 5 until the AUC score reaches a plateau.
NOTE: The DataHeroes package allows us to identify samples that are likely to be mislabeled, but it does not provide the correct labels automatically. Therefore, the cleaning process must be carried out manually. To facilitate this process, we developed a straightforward cleaning interface that saves all the suggested images to disk and generates a CSV file that lists their indices and the necessary actions for each sample. Since the manual cleaning process is tailored and time-consuming, we will only describe the primary components to maintain the article simple and concise.
The cleaning process consists of two possible actions:
- We need to validate that the label is correct. We need to switch it to the correct one if it is incorrect. For instance, if an apple is mislabeled as an orange, we need to switch it to “apple.”
- We may need to delete certain samples, which can happen in various scenarios. For instance, the class could be wrong or non-existent (although currently, we only test on oranges). Additionally, the segmentation mask may contain multiple types of objects, except for cases where there is a single occluded orange. Furthermore, the segmentation mask may be completely erroneous, meaning its coordinates do not match the object.
Important observation: It is crucial to carefully examine several samples before initiating the cleaning process to establish unambiguous rules about acceptable and erroneous labels. Without a clear understanding of what constitutes valid and harmful labels, the cleaning process may cause more harm than good.
We initialized a set of parameters that will keep updating along the cleaning process. “slim” refers to the dataset containing only oranges.
#We will clean the labels in a new copy of the initial labels arrays. y_train_slim_fixed = np.copy(y_train_slim) sample_weights_fixed = np.ones(shape=(X_train_slim.shape[0], ), dtype=np.int32) # In this variable, we will aggregate metrics across iterations. aggregated_results = initialize_aggregated_results(X=X_train_slim, y=y_train_slim_fixed)
Let’s see an example of an iteration 👇
Steps 1 & 2 of the iteration: By using the `get_important_samples()` function, we can calculate the Importance scores for all provided samples and then export the top 60 samples with the highest scores. These exported samples are saved in a custom format that enables us to perform additional cleaning processes in the future. It should be noted that the interface used for this step is specific to the problem at hand and, thus, is beyond the scope of this article.
exporting_data_iter_0 = export_top_importance( X=X_train_slim, y=y_train_slim_fixed, of_interest_class_id=of_interest_coco_class_id, export_n=EXPORT_N, iteration-aggregated_results["iteration"] )
Step 3: Each sample was manually reviewed and corrected based on one of the following actions: either select the correct label or delete the sample if the segmentation mask was found to be faulty.
Steps 4 & 5: After manually correcting the samples, the corrections were loaded from the disk and merged into `y_train_slim_fixed` and `sample_weights_fixed`. We used `y_train_slim_fixed` to select the correct label and `sample_weights_fixed` to decide whether to keep or delete the sample. The newly corrected labels were used to compute the AUC score using K-fold cross-validation.
cleaned_data_results_iter_0 = clean( service=exporting_data_iter_0["service"], X_train=X_train_slim, y_train_slim=y_train_slim_fixed, sample_weights=sample_weights_fixed, metadata_train=data["metadata_train"], iteration=aggregated_results["iteration"], )
In the end, we aggregated the results to visualize them later:
aggregated_results = aggregate_iterations( iteration_results = cleaned_data_results_iter_0, aggregated_results = aggregated_results )
NOTE: We repeated the cleaning process for ten iterations, looking at 600 segmentation masks out of a total of 6300 samples.
When should we stop the cleaning process?
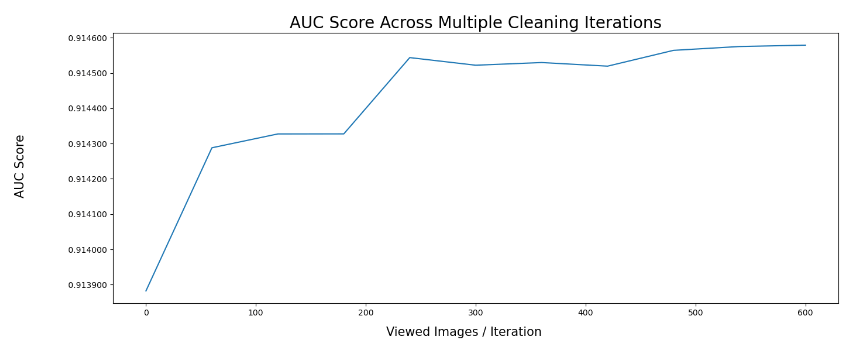
The cleaning process should be halted once we observe that the measured metric reaches a plateau. In our specific scenario, the AUC score demonstrated an increase following the first few iterations but plateaued subsequently. This indicates that ~4 iterations were sufficient for accomplishing the cleaning process.
Visualize the Final Results
AUC Score Across Iterations
Upon examining the graph below, we can observe an improvement in the AUC score merely by cleaning the labels. It is worth noting that COCO is a well-established, pristine dataset, and even under such ideal conditions, we were able to enhance the AUC score solely by cleaning the data. This approach is expected to yield even more substantial benefits in a real-world environment where the data is typically noisier and more challenging to debug. We used the newly corrected labels to calculate the AUC score through K-fold cross-validation.
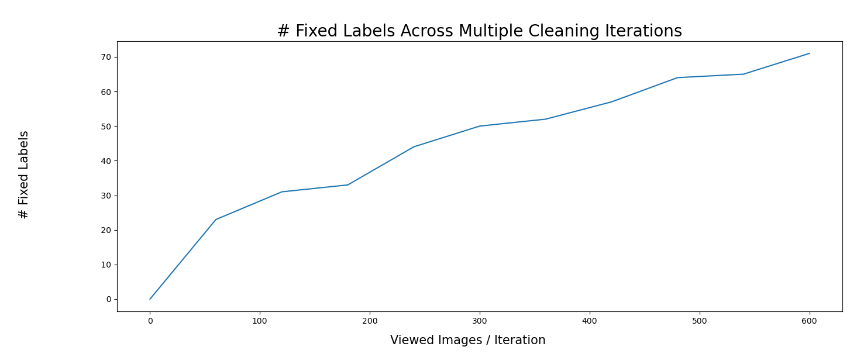
Fixed Samples Across Iterations
Using this strategy, we cleaned 11.83% of the total samples we looked at.
Let’s Take a Look at Some Dirty Samples That We Cleaned

Here we have a lemon slice labeled as an orange.

Awful. The bounding box spans multiple fruits and boxes, even a human being.

Clearly, a lemon mislabeled as an orange again.

I am not even sure what those are. Looks like a candy was labeled as an orange.

Here we have an apple mislabeled as an orange.
Despite being a well-known dataset, COCO is not as clean as one might have expected. This underscores the difficulty in labeling large datasets and highlights the crucial role of cleaning and debugging in building robust and unbiased models.
Conclusion
To summarize, the COCO dataset was cleaned for the “orange” class using the DataHeroes Coreset library. The cleaning process resulted in an increase in the AUC metric across multiple iterations, indicating the effectiveness of the cleaning. Although the cleaning was conducted for ten iterations, the AUC plateaued after the first four iterations, suggesting that the cleaning process was successful early on.
By using the DataHeroes Coreset library, we were able to speed up the cleaning process by selectively examining the top 60 samples based on their Coreset importance instead of randomly looking through samples in the hope of identifying the significant ones. This approach proved to be more efficient in identifying bugs and errors within the dataset, making it a more effective strategy for cleaning large datasets.

