
Model Quality is a metric that quantifies a machine learning model’s predictive accuracy based on observing its output derived from its input during model training, evaluation, or inference. Machine learning models that operate in critical systems primarily within sectors such as finance and healthcare are required to have high model quality, for example, a patient readmission predictive model built to precut patient’s readmission rate based on variables such as age, health condition, treatment plans, and social behavior will be required to produce a predictive output of high quality as these systems are primary dependents of other downstream systems.
There are tools to determine the quality of a model, such as confusion matrix, precision-recall, and f1 score. Some model quality measuring techniques tools are applied to specific machine learning models. For example, confusion matrices are used to determine the quality of computer vision models that solve the tasks of image classification, while quality measuring techniques such as perplexity or BLEU (bilingual evaluation understudy) scores apply to natural language processing (NLP) models that solve tasks such as language translation.
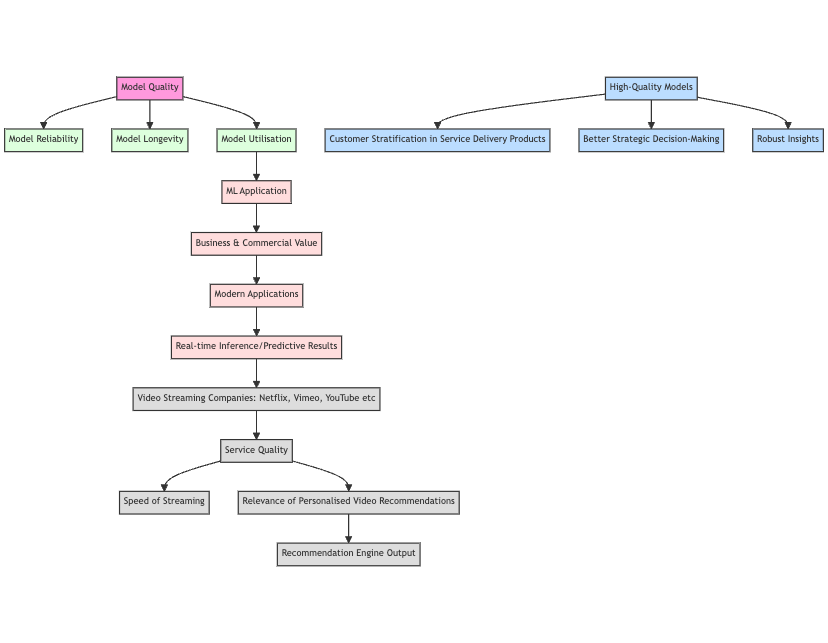
Model quality is an essential area of focus for ML/Data practitioners as it closely affects model reliability, longevity, and utilization of an ML application. Looking at the topic from a non-technical perspective can pinpoint why improved and sustained high-model quality benefits aren’t only technical. Today’s business and commercial value is realized in the features and services delivered by modern applications, which rely on machine learning models to provide real-time inference or predictive results. For example, video streaming companies such as Netflix and YouTube have the quality of their services gauged by the speed of streaming and how relevant the personalized video recommendations are to the user, which the result is inherently the output of a recommendation engine.
High-quality models lead to customer stratification in service delivery products, better strategic decision-making processes, robust insights, and more.
Another subject, model performance, accompanies the topic of model quality. As indicated earlier, a modern application that utilizes machine learning to deliver product features must take the model inference speed seriously. Losing a customer can be down to a service being delivered 10 seconds later. For example, imagine if ordering a cab on Uber took 2 minutes longer than their competitors due to the time gap between ordering and getting a ride; you’ll be more incentivized to look for alternative ride-hailing.
Model performance encompasses both the model’s predictive accuracy and operational efficiency. As mentioned earlier, predictive accuracy is gauged using metrics like accuracy, precision, recall, and F1-score, metrics associated with the model’s quality. In the context of this article, model performance will focus mainly on operational efficiency and consider the model’s speed, resource utilization, and responsiveness, especially in real-time applications.
A typical method of assessing operational performance is observing the model’s behavior during multiple inference requests and measuring the latency between making an inference request and receiving the predictive result.
There are extensive tools in the industry today that enable machine learning engineers and data scientists to profile models based on time complexity and memory utilization.
Both model quality and performance topics are typically discussed and addressed sequentially because having a high-performing model that takes a long time to deliver inference results in an overall end-user dissatisfaction, whilst having a high-performance model that delivers predictive results in real-time or near real-time. Still, the inference results are of low quality and inaccurate, which will also result in the same outcome of end-user dissatisfaction.
To better understand how to improve model quality and performance, understanding factors that affect them enables practitioners to identify areas to dedicate efforts.
Key Takeaways:
- Feature engineering improves machine learning models’ quality through feature scaling and one-hot encoding techniques.
- Model performance is boosted by techniques like algorithm optimization, parallelization, distributed computing, and hardware accelerators.
- Quantization reduces model complexity, improving performance despite potential accuracy trade-offs.
- Coresets reduce data volume for processing, improving model quality and performance.
- Coresets and Coreset Trees, combining various techniques, enhance machine learning model performance sustainably and cost-effectively.
Data Quality
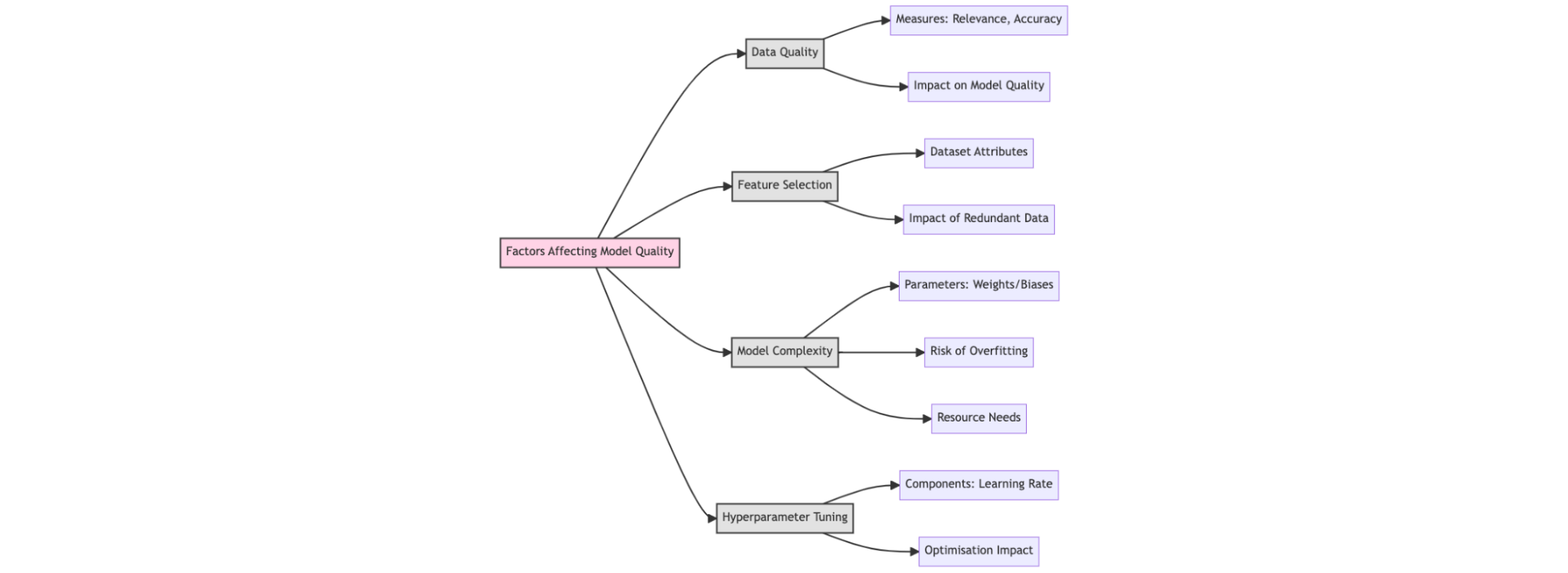
Data quality refers to the general state of the dataset used in machine learning models and systems regarding certain measures that determine their suitability for downstream tasks, such as decision-making and components in predictive systems. Data quality measures include relevance, completion, accuracy, consistency, etc.
Data quality is a crucial factor that affects model quality, as an ML model is only as good as the model it has been trained on. Therefore, the utilization of high-quality data corresponds to creating a high-quality model.
Feature Selection
Machine learning models learn directly from the features extracted and passed to the models during training. Features refer to a dataset’s attributes, data points, or variables that can be utilized for input to machine learning models during training or inference. Therefore, feature selection refers to identifying and extracting attributes of a data set that provides the internal output from the model when passed through to the model during training. Not all attributes in most aggregated datasets are helpful for defined scenarios. During data aggregation steps, it is common to collect data that are later determined as redundant as they do not increase the model predictability accuracy but instead can have the opposite effect when included. Feature selection identifies what aspect of the dataset will contribute to high-quality outputs and predictive results.
Model Complexity
Model complexity can be a vague term that encompasses different meanings. In model quality and performance context, model complexity refers to the number of parameters within the model’s neural network. Parameters within machine learning are the internal configurations of the network itself, primarily the weights and biases. During training, the weights and biases of a network are trained and modified to mimic the learning processes through backpropagation. Sometimes, the more parameters a network possesses, the more generalization power it has. However, there are scenarios where high parameter numbers in neural networks lead to overfitting, which causes poorer prediction and low-quality models. Another consideration is that complex models or models with high parameter numbers have to utilize a considerable amount of computing resources for both training and inference to stay performant and deliver predictive results at a reasonable speed.
Hyperparameter Tuning
Other model components can be modified to improve model quality and performance. The learning rate, realization parameters, dropout rate, etc., are hyperparameters. Tuning the hyperparameters during training can help optimize the model for shorter training time and better quality outputs.
Techniques for Enhancing Model Quality
Data Preprocessing
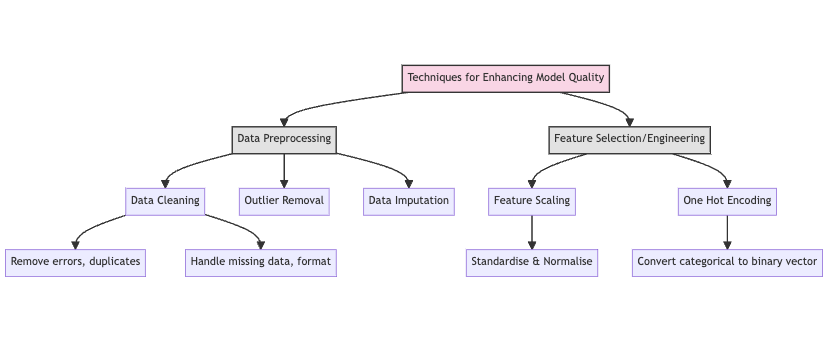
As mentioned earlier, improving data quality directly impacts model quality. Therefore, some of the best techniques and strategies for improving model quality lie in data and feature techniques. One of the techniques leveraged to improve data quality and, inherently, model quality is data preprocessing.
Data preprocessing involves the implementation or utilization of operations that are designed to take data points within a dataset from an unusable state to a desired state; some of the approaches leveraged within data preprocessing are:
- Data Cleaning: Raw data sourced from various sources such as databases, APIs, and cloud storage are not entirely in a state where they can be further passed to downstream processes within data and machine learning pipelines. Data cleaning is the process of identifying and selecting data points that do not meet the defined standards required for further data processing; typical data clearing activities include the removal of errors, deletion of special character presence, handling missing data, removing duplicate data, formatting data appropriately and addressing other data discrepancies.
- Outlier Removal: Even after data cleaning, there can be data points that are statistically different from the majority of the other data points. Outliers in the dataset can cause skew in the performance of machine learning models. Outlier removal methods are utilized to remove data points with significant variability from the other data points.
- Data imputation: There are also cases where most data points within a row of a dataset are present, but there is one missing attribute data. In scenarios where expected data is absent from the dataset, data imputation is leveraged to replace missing data using various observation techniques that consider neighboring data points or the statistical distribution of surrounding data points. Data imputation is common, and identifying missing data early in ML and data pipelines prevents problems such as model biases or inaccurate data analysis results.
Feature Selection/Engineering
Earlier, we discussed the importance of feature identification; this topic can be extended to include the selection and engineering of features to ensure they enable the model to learn the appropriate patterns in the feature set for predictions or classification, which results in high model quality and outputs.
In some scenarios, selecting the appropriate features is not enough to guarantee high model-quality output; in such cases, feature engineering becomes a process practitioners can take. Feature engineering refers to generating a new set of features or modifying existing ones to create new features that improve the model’s pattern extraction and generalization capabilities.
Examples of feature engineering techniques are:
- Feature Scaling: There are scenarios where the features extracted for model training are not within the same scale range. For example, creating a model that products an individual’s health status based on age and income can have some feature scaling issues because the range of age is from 0 to 100, whilst the range of income can range from 0 to 10,000,000. A typical machine learning algorithm such as K-Nearat Neighbour (KNN) might present issues with providing accurate predictive results since not scaling the dataset features, and the income features will have more weight on the distance metric utilized in KNN. Feature scaling prevents such issues by standardizing and normalizing the features in machine learning models and algorithms.
- One hot encoding: Machine learning models are trained on numerical attributes, but during data collection, the features are not always in an ideal state that is consumable by a neural network. For example, in classifying the colors of cars, the initial dataset might contain images of cars with an associated text label of the color. However, the neural network can process the numerical pixel representation of images of cars, but the text representation of the colors of cars cannot. In such scenarios, feature processing techniques such as one-hot encoding are leveraged to convert categorical data, such as the color of the cars, to binary vector representation. In this case, the red, blue, and orange text can be categorized and represented as the vector: [0, 1, 2].
Below are code implementations of one-hot encoding and feature scaling in action utilizing the StandardScaler and OneHotEncoder class within the preprocessing module in the SciKit-Learn library.
from sklearn.preprocessing import StandardScaler
data = {'age': [25, 45, 70, 34, 55, 67, 33, 52, 48, 23],
'income': [50000, 150000, 70000, 125000, 100000, 75000, 120000, 110000, 140000, 55000]}
X = pd.DataFrame(data)
# X is your DataFrame with 'age' and 'income' columns
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
from sklearn.preprocessing import OneHotEncoder
df = pd.DataFrame({
'color': ['red', 'green', 'blue', 'red']
})
encoder = OneHotEncoder(sparse=False)
one_hot = encoder.fit_transform(df[['color']])
df_one_hot = pd.DataFrame(one_hot, columns=encoder.get_feature_names(['color']))
print(df_one_hot)
Techniques for Enhancing Model Performance
Algorithm Optimization
Model performance does not solely depend on the model itself; it can be improved by evaluating the speed of the execution of the operation in system components that interact with the model directly or indirectly. For example, data preprocessing and feature transformation operation are crucial aspects of machine learning systems conducted in online (real-time inference) and batch (model training) machine learning scenarios. By focusing on computationally efficient operations and data structures, the time it takes to extract features from data and engineer the features into feature sets that improve model quality can be significantly reduced. The overall benefit is realized in the reduced latency when a predictive request is made and the result is provided.
Benchmark and profiling tools analyze machine learning systems and pipelines and can identify computational bottlenecks affecting overall system performance.
Parallelization and Distributed Computing
Today, some models have several tens of millions and billions of internal parameters, which make the compute resource required to store these models and enable inference almost unattainable, and even when the compute resource is available, there is a chance that degradation in model performance is likely to increase the model complexity.
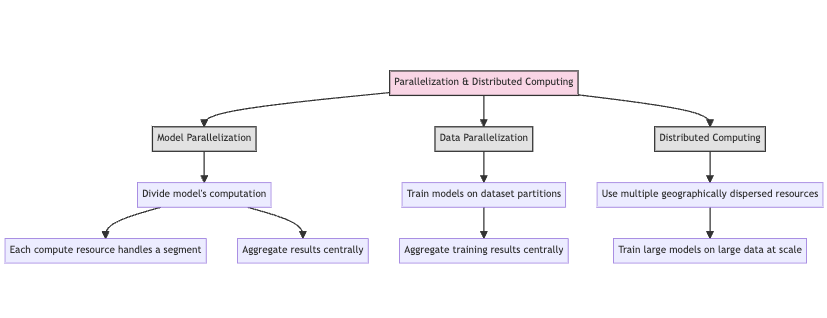
Model and data parallelization, along with distributed computing, are techniques that have emerged to solve the problem of model performance affected by model complexity and size.
- Model parallelization: When a model is too large to fit on one single hardware compute resource such as a GPU or CPU, an option considered by a number of practitioners and researchers is to divide the model’s computation across several compute, where one single compute resource holds some of the model’s layer and is responsible for calculating and modifying the parameters of it’s assigned segment of the model. Once all resources in the hardware network have completed the training step, the results are aggregated and centralized.
- Data parallelization: Data parallelization takes several models and trains them on different partitions of a large dataset. The training results across the model are aggregated and collected on a centralized model. This strategy is employed when practitioners face datasets too large to fit in a single device memory.
- Distributed Computing: Data and model parallelization are distributed computation strategies where multiple compute resources that can be located in a different location geographically work together within a network to train large machine learning models on large data at scale.
Use of Hardware Accelerators
Using more powerful computing can improve model performance(operational efficiency). In both research and commercial applications, deep learning models benefit significantly from hardware accelerators such as GPUs (Graphical Processing Units) and TPUs (Tensor Processing Units).
Reducing Model Complexity
Quantization involves reducing the structure of a neural network by employing various techniques, such as minimizing the precision and bits utilized for storing numbers in the weights and bias values within the neural network.
Weights in neural networks generally adopt 32-bit floating-point figures, which are continuous values that aid in efficiently training these networks. Post quantization, the bit representation of the numerical values in the network is diminished to smaller ‘n’ bit representations, which include 2, 4, 8, and 16-bit representations, instead of the original bit representation.
Quantization is a technique leveraged in many modern machine/deep learning models with initial sizes; quantization of large models enables the quantized variants of these models in environments with low computing and processing resources, such as mobile phones and other edge devices. It also makes them suitable for near or real-time processing due to the adopted smaller size of the model that contributes to a reduction in inference latency. Additionally, training a quantized version of a model is less demanding from a computing resource standpoint when compared to training the non-quantized version.
It should be noted that a significant disadvantage of si is that a reduction in the number of bits used for representing numerical values can lead to a substantial loss of information, which, in turn, may result in a decrease in the accuracy and performance of the model’s quantized version. Although quantization might improve model performance, there is a tradeoff for loss in model quality.
Earlier, we defined a model’s complexity as the number of parameters (weight and babies) within a model. Reducing the number of parameters in a model reduces its complexity, contributing to increased model performance, as less memory is required to store the model on devices. Pruning is a technique that reduces a machine learning model’s size (number of internal parameters) by removing neurons and connections between neurons that do not contribute to the model’s predictive capabilities. Pruning provides a method of reducing model complexity, improving model performance, and retaining model quality(predictive capabilities).
How Coresets Improve Model Quality and Performance
Looking back on our expedition into the technical landscape, we have ventured through various industry-recognized practices, methodologies, and tools to refine the quality and efficiency of machine learning models. Are all these techniques equally effective? Certainly not. Each carries unique merits and demerits, making them suitable for specialized scenarios, such as operating in low computational resource environments or dealing with data scarcity.
An intriguing area of our investigation is how to process vast amounts of data without compromising a model’s accuracy and speed – a challenge that remains at the research forefront. This problem has birthed innovative strategies like Coresets and Coreset Trees, demonstrating promising results in handling this complexity.
Originating from computational geometry, Coresets borrow from established methods like pruning, quantization, data parallelization, and distributed computing. But what exactly are Corsets? Essentially, they are a meticulously selected subset of instances from a vast dataset, each instance possessing a weight that signifies its importance. By preserving the dataset’s crucial statistical properties, we reduce the data volume for processing while keeping its quality intact, mirroring the objectives of feature scaling and algorithm optimization. This approach results in substantial resource and time savings.
Moving on to Coreset Trees, do they resemble data parallelization and distributed computing methods? Indeed, they do. Coreset Trees decompose extensive datasets into smaller, more manageable components. Coresets within these trees can be distributed across several devices, boosting computation speed. Moreover, their structure facilitates rapid model updates as new data is incorporated. This mechanism is reminiscent of distributed computing systems wherein training occurs on the updated Coreset, precluding the need to retrain the model using the entire dataset.
But how do Coresets aid in improving the quality of our models? Similar to data quality control methods, Coresets play a significant role in identifying potential data errors and anomalies. These anomalies are flagged for review in platforms such as the DataHeroes framework. Once these errors are rectified and the model is retrained on the Coreset, we can observe real-time enhancements in its performance.
Another advantage is that the reduced dataset size facilitated by Coresets allows for more efficient use of standard libraries like Sklearn or Pytorch for model training. This efficiency leads to faster hyperparameter tuning iterations without overloading computational resources. Furthermore, Coresets help to mitigate the financial and environmental costs typically associated with model training on big data and intensive hyperparameter tuning.
Thus, by synergistically amalgamating techniques like pruning, data parallelization, feature engineering, and data quality control, Coresets and Coreset Trees have emerged as revolutionary tools for enhancing the performance and quality of machine learning models more sustainably and cost-effectively. Interested in employing the in-built Coreset mechanism of DataHeroes? Then start here.
FAQ
- What is model quality, and why is it important in critical sectors like finance and healthcare?Model quality is a metric that quantifies a machine learning model’s predictive accuracy. It’s crucial in sectors like finance and healthcare, where models operate in critical systems, and their predictive accuracy is of utmost importance, such as in a patient readmission predictive model.
- What techniques can be used to determine the quality of a machine-learning model?Techniques such as confusion matrix, precision-recall, and f1 score can be used to determine the quality of a model. They are often specific to different types of models. For instance, confusion matrices are used for computer vision models, while perplexity or BLEU scores are used for natural language processing models.
- How does model performance relate to model quality?
Model performance refers to evaluating machine learning models’ efficiency, speed, and resource utilization of machine learning models. This is important as applications delivering machine learning features must ensure the speed and quality of model inference to prevent user dissatisfaction. - What factors affect model quality and performance, and what techniques can be used to enhance model quality?Factors affecting model quality and performance include data quality, feature selection, model complexity, and hyperparameter tuning. Data preprocessing, which includes techniques such as data cleaning, outlier removal, and data imputation, can be used to enhance model quality.
- What is feature engineering, and why is it important?Feature engineering refers to generating a new set of features or modifying existing ones to create new features that improve the model’s pattern extraction and generalization capabilities. It is important as it can enhance model quality and outputs.
- What are some techniques used in feature engineering?Techniques used in feature engineering include feature scaling and one-hot encoding. Feature scaling standardizes and normalizes the features in machine learning models and algorithms. One-hot encoding is used to convert categorical data to a binary vector representation.
- How can model performance be improved?Model performance can be improved through algorithm optimization, parallelization and distributed computing, hardware accelerators, reducing model complexity, and Coresets and Coreset Trees.
- What is quantization, and how does it impact model performance?Quantization involves reducing the structure of a neural network by minimizing the precision and bits utilized for storing numbers in the weights and biases values within the neural network. It can improve model performance by making models more suitable for environments with low computing resources and for real-time processing due to the model’s smaller size.
- What are Coresets, and how do they enhance model quality and performance?Coresets are a meticulously selected subset of instances from a vast dataset, each instance possessing a weight that signifies its importance. They help reduce the data volume for processing while keeping its quality intact, leading to substantial resource and time savings. Furthermore, Coresets play a significant role in identifying potential data errors and anomalies, facilitating more efficient use of standard libraries for model training, and mitigating the costs associated with model training on big data.

