
In today’s data-driven world, the data-centric approach has emerged as a powerful paradigm that prioritizes data as the central element of decision-making and development efforts. Organizations that adopt a data-centric approach recognize that high-quality data, its availability, and its accessibility are crucial for extracting meaningful insights and gaining a competitive edge in the market. This approach requires organizations to invest in data infrastructure, data management tools, and skilled professionals who can effectively capture, store, and analyze data to generate actionable insights. It also involves establishing data governance policies, data standards, and data security measures to ensure ethical and compliant data management practices.

The prospects of the data-centric approach in the field of AI and machine learning are promising. As AI and machine-learning technologies continue to evolve, the importance of data in training, validating, and deploying models will only increase. Organizations that prioritize data quality and data-centric practices will be better positioned to leverage these technologies effectively and gain a competitive advantage. Additionally, with the growing adoption of data governance and privacy regulations, the data-centric approach will become even more critical in ensuring compliance and building trust with customers and stakeholders. Embracing a data-centric approach is imperative for organizations seeking to harness the full potential of data-driven technologies in the modern business landscape.
What is the Data-Centric Approach?
A data-centric approach entails prioritizing data as a valuable resource, with an emphasis on its strategic value in driving decision-making, as opposed to considering it merely as an incidental by-product of business operations. Specifically in the context of machine learning and AI models, a data-centric approach involves the meticulous preparation of high-quality, relevant data, which has been subjected to thorough cleaning, normalization, and preparation for analysis. Moreover, this approach entails continuously monitoring and refining data to ensure its accuracy.
Why Does a Data-Centric Approach Matter?
The traditional model-centric approach to AI and ML focuses primarily on developing and optimizing the algorithm or the model. However, the data-centric approach flips the paradigm and prioritizes the quality, quantity, and diversity of the data used to train the model. The idea is that the success of a machine learning model depends heavily on the data it is trained on. High-quality, diverse, and representative data can lead to more accurate and robust models, while poor-quality or biased data can result in biased, unreliable, or ineffective models.
The Benefits of a Data-Centric Approach
Implementing a data-centric approach can offer several benefits for companies and organizations:
- Improved Model accuracy
Data is the fundamental building block of any machine learning or AI model. A data-centric approach ensures that only high-quality, relevant data is utilized in training models, thereby increasing the likelihood of producing accurate and useful results. - Streamlining the model-building workflow
Taking a data-centric approach and emphasizing data quality and relevance can aid organizations in minimizing the time and resources needed for building models. This approach also allows them to identify gaps in their data early on and take appropriate measures to address them, thus resulting in faster time-to-market. By leveraging high-quality data, organizations can generate reliable and precise models that can support informed decision-making and help them stay ahead of the competition. - Improved Business Flexibility and Responsiveness
A data-centric approach enables organizations to be more agile and adaptable to changing business requirements or new data sources. By treating data as a shared resource, organizations can ensure that their models are equipped to handle new data sources and adjust to evolving business needs, enabling them to seize new opportunities as they emerge. - Increased Model Transparency and Explainability
The data-centric approach promotes transparency and explainability in AI and ML models. By carefully curating and documenting the data used during the training process, companies can better understand how the model makes decisions, detect biases, and explain its predictions to stakeholders, customers, and regulatory authorities. - Better Adaptability to handle Data Drift
Real-world data is constantly evolving, and a data-centric approach to machine learning allows models to adapt to the changing data distributions. This involves continuous monitoring of model performance to detect any potential issues, such as data drift, and then updating and retraining the model with fresh data on an ongoing basis, resulting in more precise and up-to-date models that can effectively adapt to changes in business requirements and market dynamics. - Data Management
Data management involves various tasks such as collecting, cleaning, labeling, and ensuring the quality and integrity of the data, organizing and storing the data, and creating data pipelines for model training and inference. Proper data management ensures that the model is trained on the most relevant and accurate data and is equipped to handle any changes in the data distribution. By adopting a data-centered approach to data management, organizations can build more accurate, reliable, and transparent models. It enables them to establish proper governance, storage, and access mechanisms for data throughout its lifecycle.
How to Implement a Data-Centric Approach?
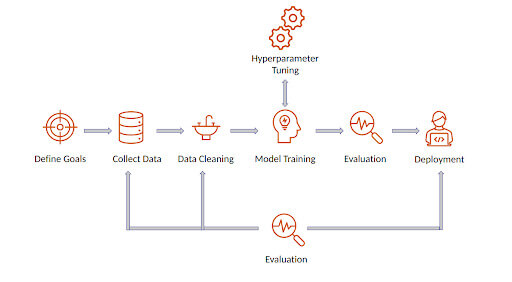
Implementing a data-centric approach requires careful consideration of various aspects of the ML workflow.
Here are some key steps to implement a data-centric approach:
- Define Clear Objectives
A fundamental aspect of any Machine Learning (ML) project is establishing unambiguous, well-defined objectives and goals. Precisely delineating the purpose and desired outcomes of the project empowers the data scientist to identify the pertinent data to collect and curate for the models. This is imperative to ensure the models are appropriately trained and accurately predict the target variable.

- Collect and Curate High-Quality Data
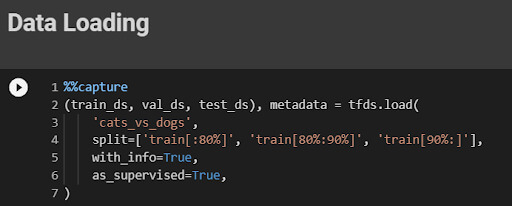
Collect diverse, representative, and high-quality data that is relevant to your ML problem. Clean and preprocess the data to remove any inconsistencies, errors, or biases. Validate the data to ensure its accuracy, completeness, and reliability.Let’s start with an example; we will use the “cats_vs_dogs” dataset. The dataset size is 786.68 MiB, and we will apply various image augmentation and train the binary classifier.In the code below, we have loaded 80% training, 10% validation, and a 10% test set with labels and metadata.

- Build Data Pipelines
Efficient data pipelines are crucial for managing and processing data in a data-centric approach. These pipelines encompass various stages, such as data ingestion, storage, pre-processing, augmentation, and labeling. By automating data pipelines, organizations can streamline their machine-learning workflow and ensure consistency and reproducibility in their data-driven processes. Automated data pipelines enable organizations to efficiently collect, store, clean, and augment data, making it readily available for machine learning models. These pipelines can also incorporate data governance practices, ensuring data quality and compliance. Overall, robust data pipelines play a critical role in optimizing the data-centric approach, enabling organizations to effectively leverage their data for ML and AI applications.

Data-centric architecture
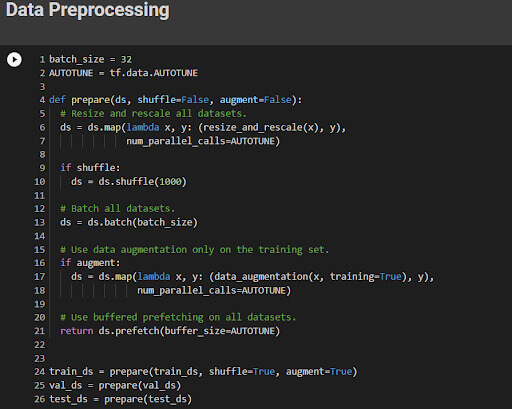
We will create a data pre-processing function to process train, valid, and test sets.
The function will:
- Apply resize and rescale to the entire dataset.
- If shuffle is True, it will shuffle the dataset.
- Convert the data into batches using 32 batch size.
- If the augment is True, it will apply the data argumentation function on all datasets.
- Finally, use Dataset.prefetch to overlap the training of your model on the GPU with data processing.

- Use Data-Centric ML Tools and Techniques
There are various ML tools and techniques that are specifically designed for data-centric approaches, such as- Data Augmentation
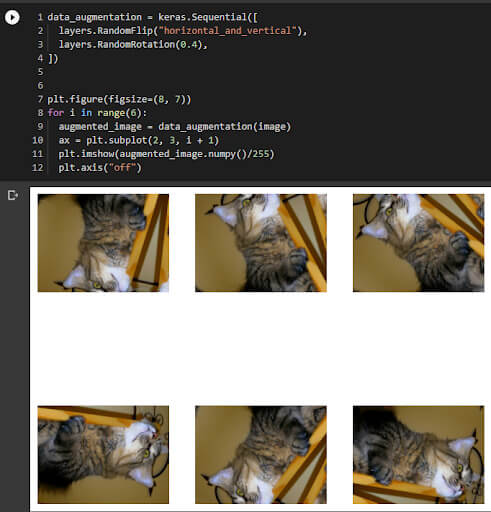
Data augmentation techniques involve generating new training data by applying transformations or modifications to the existing data. This can help increase the diversity and representativeness of the training data, leading to more robust and accurate models. Common data augmentation techniques include image rotation, flipping, scaling, and adding noise.

- Data Labelling and Annotation
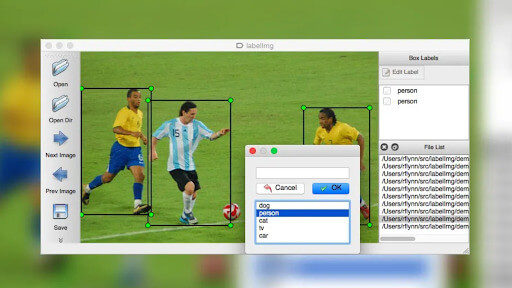
Properly labeling and annotating the data is crucial for training machine learning models. Data labeling involves assigning labels or tags to data samples to indicate their corresponding classes or categories. Annotation involves marking specific regions or objects in the data, such as bounding boxes in images. Accurate and consistent data labeling and annotation are essential for training models with supervised learning techniques.

Image source: labelimg github
- Model Iteration and Retraining
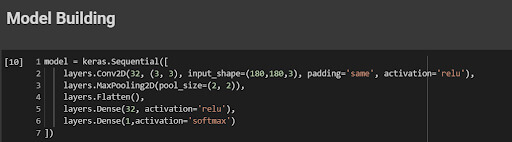
A data-centric approach recognizes that developing a machine-learning model is not a one-time process but a continuous iterative process that must continue throughout development. Continuously monitor the performance of your models in real-life scenarios and iterate and retrain them with fresh data as needed so that they can be used in real-world scenarios. As a result, the models will remain accurate, reliable, and adaptable to changing distributions of data and business requirements to remain accurate, reliable, and adaptable.We will create a simple model with convolution and dense layers. Make sure the input shape is like the image shape.

- Data Monitoring and Management
Implement robust data monitoring and management practices to ensure the quality and integrity of the data throughout the machine learning workflow. This may include regular data audits, profiling, quality checks, and versioning. Proper data management practices help ensure that the data used for training models are up-to-date, reliable, and representative of real-world scenarios.

- Model Evaluation and Bias Detection
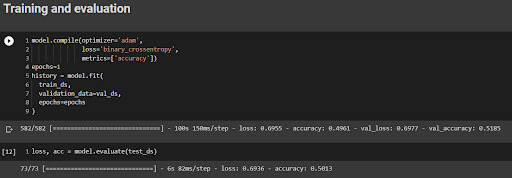
Analyze the performance of your machine learning models using appropriate metrics and techniques to evaluate their performance. Several statistical methods can be used for this, including cross-validation, hold-out validation, and others. Additionally, use techniques to detect and mitigate biases that may exist in the data. It is important to note that biases in data can lead to biased predictions and decisions based on ML models, which could have ethical, legal, and social ramifications.We will now compile the model and train it for one epoch. The optimizer is Adam, the loss function is Binary Cross Entropy, and the metric is accuracy.As we can observe, we got 51% validation accuracy on the single run.You can train it for multiple epochs and optimize hyper-parameters for better results.The model building and training part is just to give you an idea of how you can augment the images and train the model.
- Using Coresets
Coresets are smaller subsets of the original data that maintain keystatistical properties. They can reduce computational complexity without sacrificing accuracy or reliability, making them a more efficient and optimal solution than using the entire dataset.Coresets can play a significant role in a data-centric approach where the emphasis is on the data, and coresets can significantly reduce the size of data without affecting the performance, thereby allowing us to train AI models faster and more efficiently, which is especially important when working with big data.By ensuring that the model is trained on a representative subset of data points, we can reduce the likelihood of overfitting, which occurs when the model is trained to fit the training data too closely, resulting in poor performance on new data.Moreover, coresets can be used for data cleaning, which is critical in any data-centric approach. By identifying and removing anomalies, inconsistencies, and outliers from the dataset, we can ensure that the AI model is trained on high-quality data, leading to more accurate and reliable predictions.Data cleaning is essential in any data-centric approach as it ensures that the data is accurate and reliable, which is critical for developing robust AI models. By using techniques such as coresets, we can efficiently identify and remove anomalies, inconsistencies, and outliers from the dataset, leading to better data quality.Here’s a link to a previous blog post on data-cleaning automation that may be useful:[Link to Data Cleaning Automation Blog]
- Data Augmentation


The Future of Data-Centric Approaches
The data-centric approach is gaining momentum in the field of AI and ML, and its importance is expected to continue growing in the future.
As time progresses, we are likely to witness substantial progress in the realm of data-centric AI, characterized by the growing employment of automation, machine learning, and artificial intelligence tools. These will aid in the more efficient and accurate analysis of large and intricate datasets. As data becomes more abundant, diverse, and complex, companies that adopt a data-centric approach are likely to have a competitive advantage. Advances in data management, data augmentation, and ML tools and techniques are expected to further enhance the effectiveness of data-centric approaches.
In addition, the growing focus on ethics, fairness, and transparency in AI and machine learning also underscores the importance of data-centric approaches.
As the importance of data privacy and security continues to grow, data-centric approaches will need to evolve to address these concerns. By prioritizing data quality, diversity, and transparency, companies can build more responsible and trustworthy AI and ML models that are less likely to be biased, discriminatory, or unethical.
Conclusion
In conclusion, the data-centric approach is critical for machine learning and AI models. By treating data as a strategic asset, organizations can derive significant value from their data, generate valuable insights, and make data-driven decisions that drive business growth and success. This approach emphasizes data quality, diversity, and transparency throughout the machine learning workflow and requires organizations to establish robust data governance policies, invest in data infrastructure, and hire skilled data professionals. A data-centric approach can streamline the model-building process, promote transparency and explainability, and ensure regulatory compliance. Ultimately, a data-centric approach is essential for companies seeking to gain a competitive edge in today’s data-driven world.

