| Full Dataset | DataHeroes Coreset | |
|---|---|---|
| Size | 1,800,000 | 90,000 |
| # of Iterations | 75 | 75 |
| Run Time | 4,155 secs | 189 secs |
| CO2 Emissions | 35 grams | 1.5 grams |
| Accuracy | 0.860 | 0.859 |
Model Maintenance
Data drift is a common issue when moving models to production, yet always keeping your model up-to-date by continuously re-training as new data is collected is expensive and time-consuming.
Our Coreset Framework uses a unique Coreset Tree Structure (also referred to as Streaming Tree). The Coreset Tree structure allows you to add new data to the Coreset and update it on-the-go, and re-train the model using the updated Coreset in near real-time (to learn more, visit Introduction to Coresets).
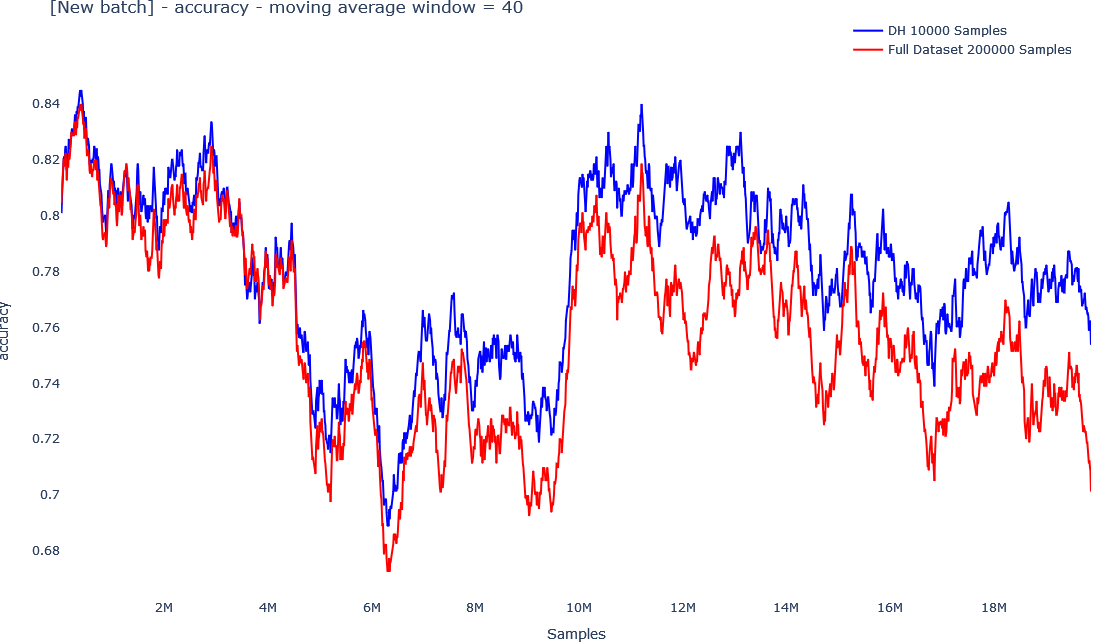
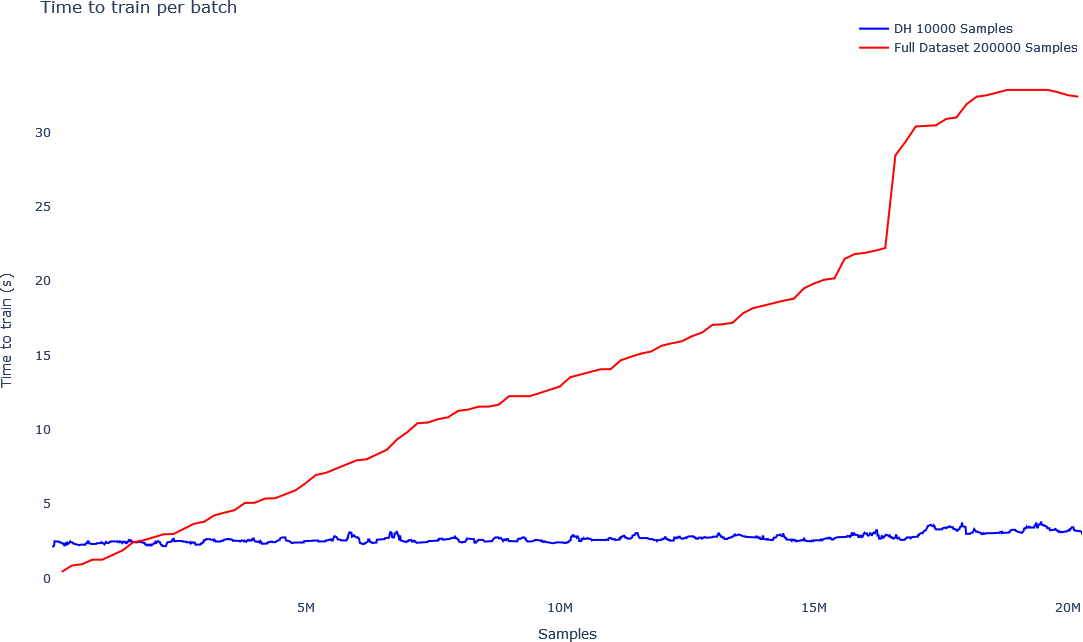
The below graphs show how data drift can be mitigated with more frequent updates. In the first graph, the red line shows the accuracy of a model in production with less frequent updates of the model (the model is re-trained every 200,000 new samples with the old data plus the new data). The graph under it shows the training time of the model. The training time of the model on the full dataset grows linearly with the size of the data, as depicted in the red line on the second graph. As more data is collected, it becomes more expensive and time consuming to train the model, and updates will become less frequent, making data drift more significant.
The blue line in the first graph shows more frequent updates (the model is re-trained every 10,000 new samples), using the Coreset Tree structure. Since the Coreset tree structure uses just a fraction of the data, the training time is significantly lower, as can be seen in the blue line in the second graph, depicting training time. Furthermore, as more data is collected, the training time of the Coreset remains almost constant, since the Coreset doesn’t grow linearly with more data, it gets updated while growing logarithmically.