

Data serves as a pivotal element in modern commercial activities, fostering informed decision-making, steering product ideation, and shaping marketing strategies. However, data does not endure as a constant entity and instead undergoes alterations over time. The notion of data being subject to transformation over time is referred to as data drift. Data is characterised by its statistical parameters, encompassing key measures such as the mean, variance, distribution, and correlation. Any modifications to these parameters can result in deviations from the anticipated performance of the model trained on the original data. Data drift, therefore, can transpire because of multiple factors, ranging from alterations in the business landscape to shifts in data collection protocols, data storage infrastructure, and data processing frameworks.
Data drift can have significant consequences on business operations, including inaccurate predictions, flawed decision-making, and a loss of competitive advantage. In this blog, we will examine what data drift is, why it happens, and how businesses can manage it.
In today’s world, machine learning models have become an integral part of various industries, ranging from healthcare and finance to retail and social media. These models rely on a large amount of data to learn and make predictions, providing businesses with valuable insights into customer behaviour, market trends, and operational efficiency. However, the effectiveness of these models can be impacted by a range of issues that affect their performance, one of which is data drift.
What is Data Drift?
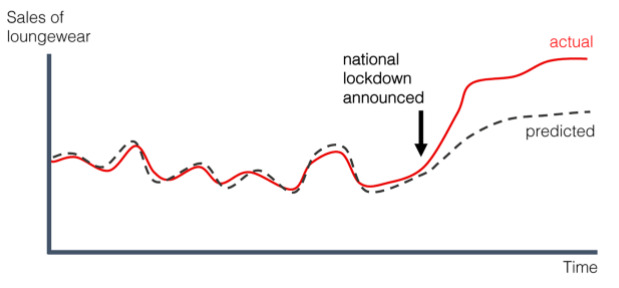
Source: Neptune
Machine learning models have become indispensable components of various industries, such as healthcare, finance, retail, and social media, as they provide businesses with critical insights into customer behaviour, market trends, and operational efficiency, leveraging a plethora of data for learning and prediction. However, despite their exceptional capabilities, machine learning models can be hindered by a range of issues, one of which is data drift.
Data drift is a phenomenon that occurs when the statistical properties of the input data or the target variable of a model change over time, causing the model’s performance to deteriorate. This means that the model becomes less effective at making accurate predictions because it is no longer optimised for the current state of the data. The underlying reasons for data drift can be diverse and multifaceted, such as changes in user behaviour, the introduction of new variables or features, or shifts in the underlying distribution of the data.
What does Concept drift mean?
Concept drift refers to the phenomenon where the statistical properties of the target variable undergo a change over time, rendering the originally trained model less effective. This happens because when a model is built, it is trained to map the independent variables (predictors) to the target variable, but when the statistical properties of the target variable shift, the mapping becomes less effective, resulting in diminished model accuracy. Concept drift can occur due to multiple factors, including changes in the environment, data collection processes, data storage infrastructure, or data processing pipelines.
Concept drift can occur in different ways, and it is essential to understand the different types to identify and address them effectively.
Some of the types of Concept Drift include
-
Sudden Drift
Sudden drift occurs when the relationship between input and output data in a machine learning model changes abruptly and significantly, which can be caused by various factors such as changes in data source, user behaviour, or environment. Detecting and addressing sudden drift is critical to maintain the reliability and robustness of machine learning models. Examples of sudden drift can be seen in the stock market, healthcare, e-commerce, and transportation industries, where unforeseen events, unexpected outbreaks, changes in consumer preferences, and shifts in traffic or weather conditions can cause a significant transformation in the relationship between the input and output data of machine learning models.
-
Gradual Drift
Gradual drift is a manifestation of concept drift in machine learning models, which is characterised by a gradual shift in the fundamental concept or relationship between the input and output data over an extended period. The causes of gradual drift are multifaceted and may include changes in the user behaviour, variations in the data source, or other external factors. Such a phenomenon, while not as abrupt as sudden drift, can still have a significant impact on the accuracy and reliability of machine learning models. An example of gradual drift can be seen in the energy industry where gradual drift can occur due to changes in energy demand or the emergence of new energy technologies, leading to a gradual shift in the relationship between input data (energy consumption) and output data (energy production and distribution).
-
Recurrent Drift
Recurring drift is a type of concept drift in machine learning models that manifests as a periodic change in the relationship between input and output data. Recurring drift can occur due to a range of reasons, including seasonal changes, recurring events, or changes in user behaviour. The periodicity of recurring drift sets it apart from other types of concept drift, requiring a tailored approach to detection and mitigation. For instance, seasonal changes can result in recurring drift in retail sales or weather patterns, causing a shift in input-output relationships. Similarly, recurring events such as holidays or cultural events may cause recurring drift in customer behaviour.
Data Drift vs Concept Drift
While data drift is often used interchangeably with concept drift, there is a subtle difference between the two. Data drift refers to changes in the input data distribution, while concept drift refers to changes in the relationship between the input data and the target variable.
For instance, in a fraud detection model, data drift may occur if the frequency of fraudulent transactions changes over time, while concept drift may occur if the characteristics of fraudulent transactions change over time, making them more difficult to distinguish from non-fraudulent transactions.
Some other types of Data Drift
There are several more types of data drift that can occur
-
Population drift
It is a type of data drift that refers to the change in the distribution of data over time. For instance, if a machine learning model is used to predict customer churn, the demographic characteristics of the customer base may change over time, resulting in a shift in the data distribution. This can cause the model’s accuracy to decline, as the model was not trained on the new distribution of data.
-
Covariate shift
It refers to the type of data drift that occurs when the distribution of a specific variable in the data changes over time. For instance, if a machine learning model is used to forecast the price of a commodity, the variables such as supply and demand that influence the price may change over time, leading to a shift in the distribution of the commodity’s price data.
-
Label drift
This occurs when the labels or target values associated with the data change over time. For example, in a model used to predict fraud, the definition of fraud may change over time, leading to a change in the label distribution.
What are the best ways to detect drift?
Detecting drift is crucial to ensure that machine learning models remain accurate and effective. Here are some ways to detect drift.
-
Monitoring performance metrics
One of the easiest ways to detect drift is by monitoring the model’s performance metrics, such as accuracy, precision, and recall, over time. A sudden drop in these metrics could indicate that the model is no longer optimised for the current state of the data.
-
Statistical tests
Statistical tests, such as the Kolmogorov-Smirnov test or the Chi-squared test, can be used to compare the distribution of the input features over time. If the distribution changes significantly, it could indicate data drift.
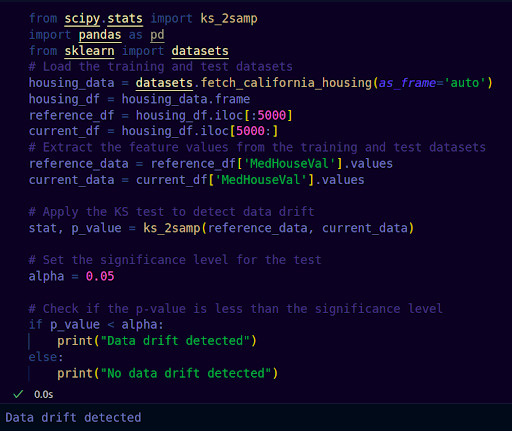
Let’s take an example of the California Housing Dataset. We can use the KS Test to detect data drift of any feature

Here, we can see data drift is detected for the feature “MedHouseVal” -
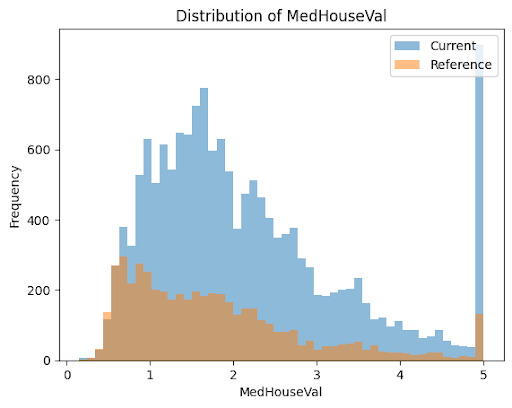
Data Visualization
Data visualisation techniques can be used to visualise changes in the input data distribution over time. For instance, a histogram or density plot can be used to visualise changes in the frequency or density of the input features.
We can Visualise the current and reference data to see the changes in the data distributions


-
Drift detection algorithms
Several drift detection algorithms, such as the Drift Detection Method (DDM) and the Early Drift Detection Method (EDDM), have been developed to automatically detect data drift in real-time. These algorithms monitor the model’s performance over time and alert data scientists if there is a significant drop in performance.
How to prevent drift?
Preventing drift is essential for ensuring the continued effectiveness of machine learning models. Here are some best practices for preventing drift
1. Regular Model Retraining
One of the most effective ways to prevent drift is to regularly retrain your machine learning models with new data. This can help the model adapt to changes in the data distribution and target variable, ensuring that it remains optimised for the current state of the data.
However, retraining models on a large dataset can be expensive and time consuming. It involves the use of significant computational resources that can lead to longer training times and increased memory usage, making the retraining process more challenging while also having a negative environmental impact. The energy required to power the computing resources for model training can have a significant carbon footprint.
One approach to mitigating the challenges associated with retraining models on large datasets is the use of coresets.
Coresets are a set of representative samples from a larger dataset that preserve the salient features of the original data and approximate the performance of the full dataset. By using coresets, machine learning models can be retrained on a smaller, more manageable dataset that captures the essential features of the original data which reduces the computational cost and time required for retraining. As a result of the reduced computational cost, Coresets can contribute to the reduction of carbon emissions associated with model training. This is especially significant for deep learning models trained on large datasets, which can require weeks or even months to process. Coresets can improve the efficiency and accuracy of a model, while also making it more robust to changes in the data distribution.
Using coresets for drift management has several advantages. First, by monitoring the error rate of the model on a smaller subset of the data, it is possible to detect drift more quickly and accurately than if the full dataset were used. This is because coresets are designed to capture the most important information in the data, which can help to identify when the relationships between variables have changed.
Furthermore, coresets can be dynamically updated more frequently with new data ensuring that the model is continuously optimised for the current state of the data. This is because unlike the full dataset, coresets don’t grow linearly with new data. Instead, the growth of coresets is logarithmic, which means that as the dataset size grows, the size of the coresets required to maintain accuracy and preserve salient features remains relatively small. This logarithmic growth ensures that the computational cost and time required for retraining are significantly reduced. This is important because it allows the model to adapt to changes in the data distribution faster thereby avoiding unnecessary drift.
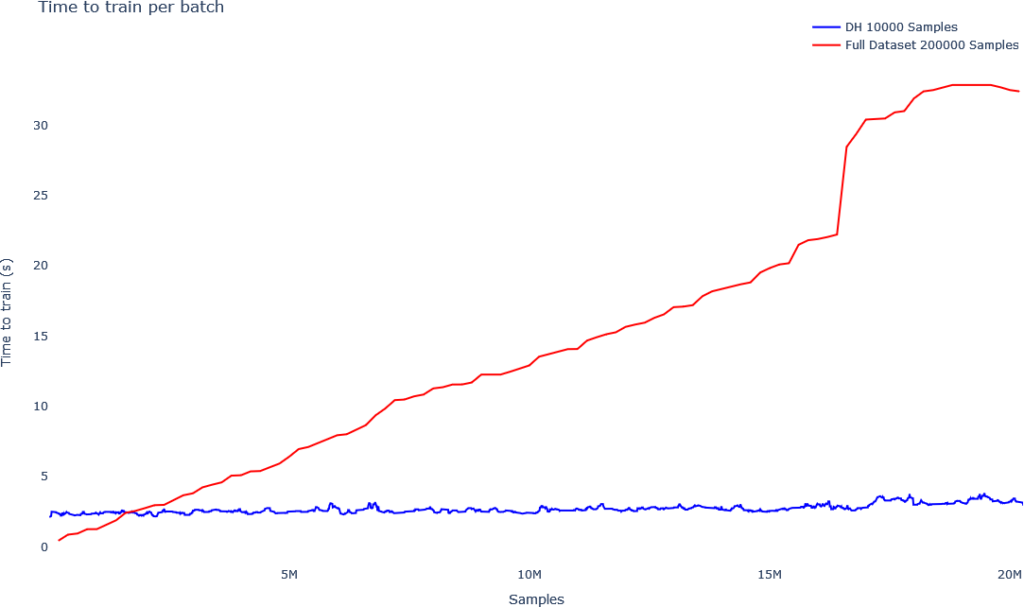
Source: dataheroes
This graph shows how the training time for the full dataset increases linearly with new data, but time taken to train the model on a coreset (blue line) remains almost constant.
2. Feature selection
Choosing the right set of features can help to prevent drift by ensuring that the model is focused on the most relevant and stable features. This can help to reduce the impact of changes in the data distribution on the model’s performance.
3. Data Augmentation
Data augmentation techniques can also be useful for preventing drift. By generating synthetic data points or modifying existing data points, data augmentation can help to balance the distribution of the data and reduce the impact of outlier data points.
4. Drift Analysis
Drift analysis can be used to identify potential sources of concept drift in your machine learning models. This involves comparing the predictions of your model against a baseline or ground truth to identify when the model’s performance begins to deteriorate. By analysing the data and features that contribute to the drift, you can develop strategies for preventing or mitigating the effects of drift.
5. Monitoring model performance
Monitoring the performance of the model over time can help to identify when drift is occurring. If the model’s performance deteriorates over time, this may be a sign of drift, and action can be taken to address it. In real-world scenarios, monitoring for drift is crucial for preventing performance degradation in machine learning models. This can involve tracking the performance metrics of your model over time, such as accuracy or AUC, and comparing them against historical baselines. You can also use techniques such as residual analysis or clustering to identify patterns of drift in your data and adjust your model accordingly.
For instance, in a fraud detection model, you may monitor the frequency of fraudulent transactions and adjust the model’s parameters to handle changes in the frequency of fraudulent transactions. In a predictive maintenance model, you may monitor the distribution of sensor data and adjust the model’s features to handle changes in the distribution.
What is a drift detection system?
A drift detection system is an essential component of any robust machine learning system, as it enables the timely detection of changes in the underlying data distribution that can impact the accuracy of the model.
A Drift detection system constantly monitors a machine learning model’s performance and compares it to the expected performance based on prior performance and input data. If the deviation between the anticipated and actual performance surpasses a specific threshold, the system highlights it as potential drift and notifies the data scientists or developers to act.
Various techniques such as statistical tests, machine learning algorithms, and rule-based methods can be used by drift detection systems to identify drift. Common methods include analysing the data distribution, measuring the error rate, comparing the model’s predictions with the actual outcomes, or tracking the changes in the feature importance. The selection of a specific technique is based on various factors, such as the type of model, the nature of the data, and the specific requirements for drift detection.
Once the drift detection system is in place, it must be regularly monitored and evaluated to ensure it is performing effectively. This includes measuring the system’s accuracy and precision in detecting drift, as well as its ability to adapt to changes in the data and maintain the model’s accuracy.
Machine learning techniques such as feature selection or data augmentation can be implemented to enhance the effectiveness of the drift detection system and improve the model’s robustness to changes in the data distribution. Furthermore, automated retraining of the model may be considered to ensure its optimization for the current state of the data.
Automation of Drift Detection
Automating drift detection has become increasingly popular due to the time-consuming and resource-intensive nature of manual intervention. There are now a variety of tools and platforms that enable the automation of these processes.
Here are some benefits of automating drift detection
-
Increased Efficiency
Automating drift detection can save time and resources by reducing the need for manual intervention. With automated systems in place, machine-learning models can be continuously monitored and updated with minimal human intervention.
-
Faster Response Time
Automated systems can also respond more quickly to changes in the data distribution or target variable, allowing for more rapid model adaptation and retraining.
-
Reduced Error Rates
Automation can also reduce the likelihood of errors in the detection and prevention of drift. Automated systems can analyze large amounts of data more accurately and consistently than human operators, reducing the risk of human error.
Automated Machine Learning Platforms
There are now several tools and platforms that enable automated drift detection. Automated machine learning platforms such as H2O.ai, DataRobot, and Google Cloud AutoML enable automatic generation and optimization of machine learning models, including automated drift detection and model retraining.
Limitations of Automated Solutions
While automation can bring many benefits to the detection and prevention of drift, it is important to note that automated systems are not fool proof. There may be scenarios where human oversight and intervention are necessary, such as when dealing with complex or unexpected changes in the data distribution or target variable. Therefore, it is crucial to have a well-designed and comprehensive monitoring and management strategy in place to ensure the reliability and effectiveness of automated drift detection.
Conclusion
The impact of data drift on the performance of machine learning models can be significant. As the model becomes less effective at making accurate predictions, its overall performance can deteriorate, leading to suboptimal outcomes and potentially significant financial or reputational losses. In some cases, data drift can also lead to unintended consequences, such as bias or discrimination in the model’s predictions. Therefore, it is crucial to detect and address drift as early as possible to ensure the continued effectiveness of the model.
To address drift, data scientists and developers must regularly monitor and retrain their machine learning models to ensure they remain optimised for the current state of the data. They may also implement techniques such as feature selection or data augmentation to adapt the model to changes in the data distribution or target variable. In some cases, it may also be necessary to modify the model architecture or algorithm to improve its ability to handle drift. Additionally, Automated Drift Detection systems can be used to improve efficiency and reduce errors.

