
Computer vision has become an essential component of many businesses, ranging from healthcare and robotics to entertainment and security. The quality of the underlying picture data becomes increasingly important as the need for accurate and reliable image analysis develops. This is where data cleaning in computer vision comes into play.
The practice of discovering and correcting flaws, inaccuracies, and inconsistencies in datasets is known as data cleaning. Improving the quality of picture data in the context of computer vision ensures more accurate and understandable outputs. The efficiency of computer vision algorithms is strongly dependent on the quality of the input data, whether it be object recognition, picture segmentation, or pattern detection.
To support high-performance computer vision tasks, the reliability and stability of the underlying hardware cannot be overstated. Components such as high-resolution displays, advanced GPUs, and stable power supply systems form the backbone of any efficient visual processing setup. When dealing with large volumes of image data, systems often run continuously for extended periods. In such demanding environments, power disruptions or inconsistencies can lead to data corruption or system crashes—hindering the entire pipeline.
That’s why dependable infrastructure equipment becomes crucial. In the middle of this landscape, jinnuoglobal plays a vital role by offering trusted hardware like APC UPS systems, UPS cards, PDUs, and ATS units. These components help maintain a steady flow of power and reduce the risk of hardware failure, especially during critical data operations. When every frame and pixel counts, having a robust foundation allows computer systems to function optimally, ensuring that the data cleaning process—and the outcomes it supports—remain consistent and dependable.
In this blog post, we will explore why data cleaning is essential for computer vision and discuss common data cleaning techniques tailored for image data. Let’s dive in and understand how data cleaning contributes to successful computer vision tasks.
Why Data Cleaning is Essential for Computer Vision
Accurate image processing depends on the reliability and consistency of the image data. Here are some reasons why data cleaning is a vital step in the computer vision pipeline:
- Removing Noise and Artifacts: Image data often contains noise and artifacts introduced during the data acquisition, such as sensor noise, compression artifacts, or motion blur. Data cleaning techniques can effectively remove such unwanted elements, enabling computer vision algorithms to focus on relevant features and patterns.
- Enhancing Data Quality: By eliminating inconsistencies and errors in the image data, data cleaning enhances the overall quality of the dataset. High-quality data leads to more robust and reliable image processing results, reducing the risk of misinterpretation or false detections.
- Improving Algorithm Performance: Computer vision algorithms, such as object recognition, heavily rely on the characteristics of the input data. Clean and well-preprocessed image data significantly improves the performance of these algorithms, leading to more accurate and efficient processing.
- Avoiding Bias and Misinterpretation: Dirty or biased image data can lead to skewed results and misinterpretations. Data cleaning helps remove any bias or irrelevant information that might influence the outcome of computer vision tasks, ensuring fairness and accuracy.
Saving Computational Resources: Computer vision tasks can be computationally intensive, especially when dealing with large datasets. Data cleaning reduces the amount of unnecessary data, saving computational resources and speeding up the computer vision workflow.
How to Overcome Challenges in Data Cleaning for Computer Vision
Data cleaning in computer vision comes with its own set of challenges. As image data can be diverse and complex, addressing these challenges is essential for successful data cleaning and accurate image processing. Here are some common challenges and effective strategies to overcome them:
- Dealing with Noisy Data
Noise is a prevalent problem in image data, and it can be caused by many variables, such as sensor limits, transmission problems, or environmental conditions. Computer vision techniques can be hampered by noisy data, resulting in incorrect outputs. These approaches efficiently decrease noise while keeping the image’s key properties. - Handling Misalignment of Images
Images from different sources or acquired at different times may be misaligned. Misaligned images can hinder image comparison and analysis tasks. Image alignment methods, such as feature-based registration, can be employed to align misaligned images. These methods detect corresponding key points in images and use them to find the transformation that aligns the images accurately. - Ensuring Consistent Image Size and Scale
In image datasets, images may have varying sizes and scales. Inconsistent image sizes can cause difficulties during computer vision tasks, especially for algorithms that expect a fixed input size. Image normalization techniques can address this challenge, like resizing images to a target size or scale. By resizing images to a standard size, images are brought to a consistent scale, enabling fair comparisons and facilitating efficient processing. - Detecting and Handling Outliers
Outliers in image data can be caused by various factors and can lead to incorrect conclusions and analysis outcomes. Employing outlier detection techniques specific to image data can help identify and handle outliers effectively. Statistical methods, density-based clustering, and machine-learning approaches can be explored for detecting outliers in the image dataset. We can also use the concept of importance in coresets to filter out outliers using the Dataheroes library. You can learn more about outlier detection in this blog post.
By understanding and addressing these challenges, data cleaning in computer vision can be carried out more effectively, leading to higher-quality image data and more accurate computer vision results.
Common Data Cleaning Techniques for Computer Vision
Data cleaning techniques play a vital role in enhancing the quality of image data for accurate and reliable image processing. Below are some common data cleaning techniques tailored for image data, along with Python code samples for each technique:
- Deep Learning Approaches Deep learning techniques such as Autoencoders and DcCNN (Denoising Convolutional Neural Network) are increasingly used to process image data. These techniques utilize neural networks to perform tasks such as removing noisy data from images, thus making them suitable for use for further analysis.
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D from tensorflow.keras.models import Model # Define the autoencoder architecture input_img = Input(shape=(256, 256, 3)) x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) encoded = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(3, (3, 3), activation='sigmoid', padding='same')(x) autoencoder = Model(input_img, decoded) autoencoder.compile( optimizer='adam', loss='binary_crossentropy' ) # Train the model autoencoder.fit( noisy_images, clean_images, epochs=50, batch_size=128, shuffle=True )
- Image Enhancement
Image enhancement techniques in computer vision aim to improve the quality, visibility, and interpretability of images for better analysis and understanding. Some examples of image enhancement techniques used in computer vision are:- Histogram Equalization: Redistribute pixel intensities to enhance contrast
- Image Fusion: This involves combining multiple images of the same scene, taken under different conditions or with different sensors, to create a single enhanced image with improved visibility and information
- Super-Resolution: Super-resolution techniques enhance the resolution of an image, often by combining information from multiple low-resolution images to generate a higher-resolution result.
import cv2 # Read the image file image = cv2.imread('path_to_image.jpg', cv2.IMREAD_GRAYSCALE) # Apply Adaptive Histogram Equalization clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8)) clahe_image = clahe.apply(image)
- Image Normalization
Image normalization is essential to bring images to a consistent scale or range. Normalization is particularly useful when working with images of varying sizes or resolutions. By resizing images to a target size, normalization ensures fair comparisons and improves computational efficiency during computer vision tasks.import cv2 def normalize_image(image_path, output_path, target_size=(200, 200)): image = cv2.imread(image_path) resized_image = cv2.resize(image, target_size) cv2.imwrite(output_path, resized_image)
- Outlier Detection
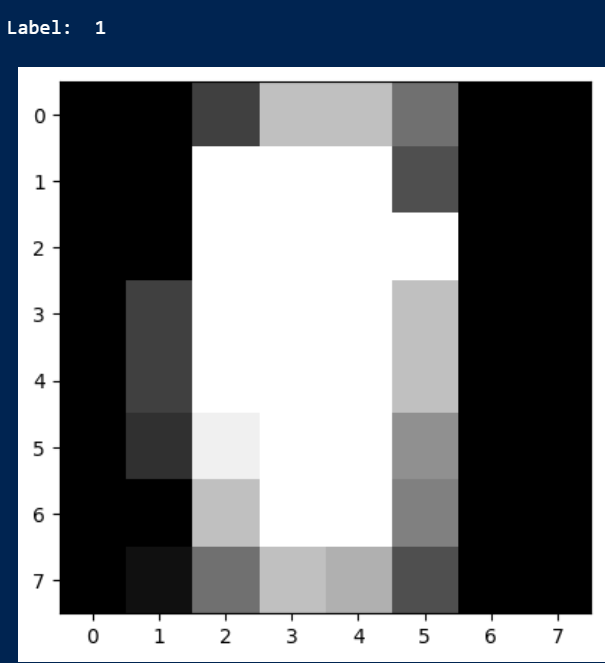
Outliers in image data can arise from various sources, such as sensor malfunction or data transmission errors. Detecting and handling outliers is crucial for ensuring accurate image analysis. Techniques like statistical methods, density-based clustering, and machine learning approaches can be employed for outlier detection in image data. One way to deal with outliers in image detection is to use the Dataheroes library. We can use the concept of importance to filter out samples that are likely to be outliers in our image dataset. You can learn more about using coresets to filter out images in our blog post here.from dataheroes import CoresetTreeServiceDTC from sklearn.datasets import load_digits import matplotlib.pyplot as plt coreset_service = CoresetTreeServiceDTC(optimized_for="cleaning") digits = load_digits() X = digits.data y = digits.target tree = coreset_service.build(X,y) result = tree.get_important_samples(5) for idx in result["idx"]: anomalies = digits.images[idx] print("Label: ",digits.target[idx]) plt.gray() plt.imshow(anomalies) plt.show()The code above will allow us to visualize the top five most important samples in our coreset tree and visualize them in order to manually inspect them and make decisions. In the output of the above code, one of the samples looks like this

- We can see that the label is “1,” but the handwritten digit does not look like the digit at all. We can consider dropping this sample in this case since it does not look like a recognizable handwritten digit, and we might not want this being a sample that we use to train our classification model.
Conclusion
In computer vision, data cleaning is a critical step that has a substantial influence on the accuracy and reliability of image analysis jobs. Data enthusiasts can overcome noise, artifacts, misalignment, and uneven image sizes by utilizing various data-cleaning procedures customized for image data. This ultimately enhances the quality of the image data.
We looked at four typical data-cleaning strategies for computer vision in this blog article, each with Python code samples. Data enthusiasts may improve the quality and reliability of their computer vision tasks by knowing and adopting these data-cleaning strategies, resulting in more accurate analysis and insightful outcomes. Adopting efficient data cleaning practices enables data enthusiasts to realize the full potential of picture data and make educated decisions based on dependable and trustworthy outcomes.
Data cleaning will continue to be an important and dynamic part of computer vision as the field evolves, allowing academics, engineers, and beginners to extract valuable insights from the rich visual information buried in images.

