Build a Better ML Model. 10x Faster.
Reduce your dataset to a small subset that maintains the statistical properties and corner cases of your full dataset.
Use standard libraries to explore, clean, label, train and tune your models on a smaller subset, and build a higher quality model, faster.
Reduce Dataset Size without Losing Accuracy
| Training Dataset size | % of full dataset | AUC | |
|---|---|---|---|
| Full dataset | 580,440 | 100% | 0.780 |
| Random Sample 1% | 5,804 | 1% | 0.725 |
| Random Sample 15% | 87,066 | 15% | 0.778 |
| DataHeroes Coreset 1% | % | 0.780 |
- from dataheroes import CoresetTreeServiceLG
- service_obj = CoresetTreeServiceLG(optimized_for='training', n_instances=580440)
- service_obj.build(X, y)

Build a Better Model (by Systematically Finding and Fixing Errors in Your Data)
Every model is only as good as the quality of the data used to train it. But finding errors in a large dataset is like finding a needle in a haystack. The DataHeroes framework uses the Coreset attributes to systematically identify potential errors and anomalies and flag them for review. Fix the errors and see your model update in real time as the model is re-trained on the Coreset.
- indices, importance = service_obj.get_important_samples(class_size={‘non_defect’: 50})
- service_obj.update_targets(indices, y=[‘defect’] * len(indices))
| Full Dataset | DataHeroes Coreset | |
|---|---|---|
| Size | 1,800,000 | 90,000 |
| # of Iterations | 75 | 75 |
| Run Time | 4,155 secs | 189 secs |
| CO2 Emissions | 35 grams | 1.5 grams |
| Accuracy | 0.860 | 0.859 |
Save Time, Money & CO2 (by Training Your Model on the Coreset)
Use Sklearn, Pytorch or other standard libraries to train your model orders of magnitude faster on the Coreset or run many more hyperparameter tuning iterations to improve model quality without requiring excessive compute resources.
- gs = GridSearchCV(model, grid_params, scoring='roc_auc_ovo')
- coreset = service_obj.get_coreset()
- indices_coreset, X_coreset, y_coreset = coreset['data']
- gs.fit(X_coreset, y_coreset, sample_weight=coreset['w'])
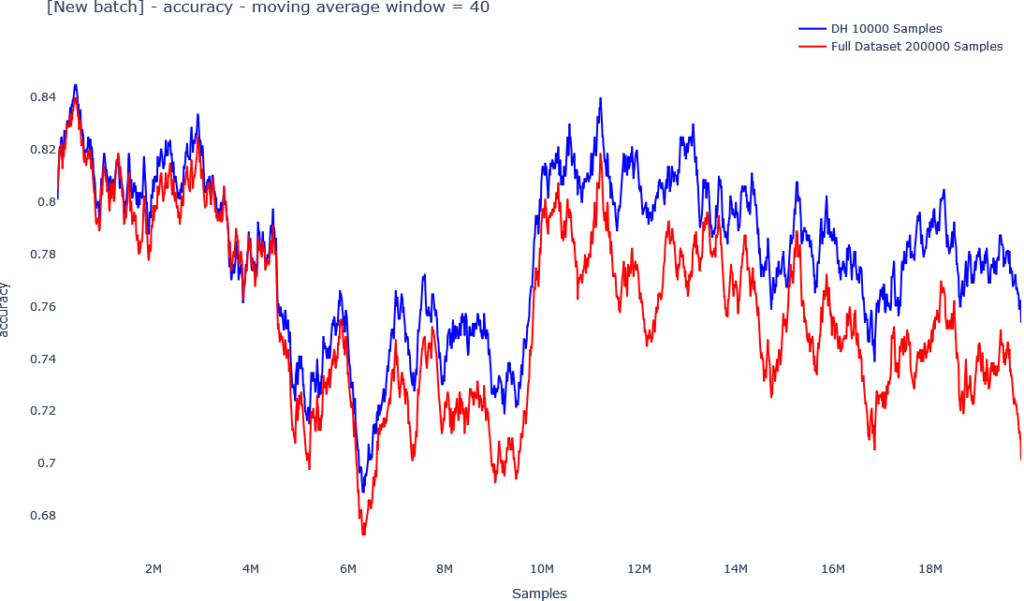
Avoid Data Drift (by Continuously Updating Your Model on the Coreset)
Data drift is a common issue when moving models to production, yet always keeping your model up to date by continuously re-training as new data is collected is expensive and time consuming. Our unique Coreset tree structure allows you to add new data and update the Coreset on-the-go, and re-train your model on the Coreset in near real-time.
Ready to Get Started?


Our unique Coreset Tree Structure (also referred to as Streaming Tree) allows you to update labels or delete data instances and immediately see how the changes affect your model without requiring re-computation of the model on the full dataset.
The below graphs demonstrate the effect on balanced accuracy of identifying and fixing labeling errors using the Importance property, relative to random.

Data Cleaning
The DataHeroes framework uses a Coreset property referred to as Importance (or Sensitivity) to systematically identify potential errors and anomalies in your data.
When computing a Coreset, every instance in the data is assigned an Importance value, which indicates how important it is to the final machine learning model. Instances that receive a high Importance value in the Coreset computation require attention as they usually indicate a labeling error, anomaly, out-of-distribution problem or other data-related issue.
Reviewing the instances with the highest importance will uncover many errors. The below histogram illustrates how clean and noisy data can be separated by using the Importance value.
| Full Dataset | DataHeroes Coreset | |
|---|---|---|
| Size | 1,800,000 | 90,000 |
| # of Iterations | 75 | 75 |
| Run Time | 4,155 secs | 189 secs |
| CO2 Emissions | 35 grams | 1.5 grams |
| Accuracy | 0.860 | 0.859 |
Training and Hyperparameter Tuning
Training your model on big data or running hyperparameter tuning can consume significant compute resources and energy and take significant time and expenses. Using distributed solutions such as Spark (when possible) can speed up compute time but will still consume significant energy and incur significant cost.
Using our much smaller Coreset structure, you can train or tune your model orders of magnitude faster and consume significantly less compute resources and energy, without impacting model accuracy. Just use DataHeroes to build the Coreset and then use any standard library such as Sklearn or Pytorch to train the model or use DataHeroes’ library built-in training mechanism.
If you are still developing your model, you can do quick iterations of data cleaning and training on the Coreset, and see your model improve in real-time. If you’ve finished development and want to do hyperparameter tuning, run your hyperparameter tuning on the Coreset and test many more iterations at a fraction of the time to find the optimal hyperparameters for your model.
Model Maintenance
Data drift is a common issue when moving models to production, yet always keeping your model up-to-date by continuously re-training as new data is collected is expensive and time consuming.
Our Coreset Framework uses a unique Coreset Tree Structure (also referred to as Streaming Tree). The Streaming Tree structure allows you to add new data to the Coreset and update it on-the-go, and re-train the model using the updated Coreset in near real-time.
Go from updating your model every few weeks to updating it daily, multiple times a day or at any frequency of your choosing using our Coreset framework, and avoid unnecessary data drifts.